Vercel AI的 适配器设计模式
我发现最近在学习大模型的 agent 的开发的时候呢
很多异常场景其实没办法完全通过真实的大模型复现
比如说 tools 的循环调用,API 的 429 等异常场景,不能很好的通过真实大模型去复现测试!
所以再开发的环境下,写一个 MockModel,让我们去 Mock 各种异常的场景还是很有必要的!
pnpm add ai @ai-sdk/openai dotenv
pnpm add -D typescript tsx @types/nodeai是 Vercel 的 AI SDK@ai-sdk/openai是 OpenAI 兼容协议的适配器
AI SDK 采用的是 Provider 模式——核心包 ai 定义统一接口j
interface LanguageModel {
doStream(options): Promise<{ stream: AsyncGenerator }>
}
// 统一流格式(不管哪家AI,都转成这个)
type StreamPart = { type: 'text-delta', textDelta: string }每个模型厂商出一个 Provider 来适配自己的 API !
/ =========================
// OpenAI 驱动:实现规矩
// =========================
class OpenAIModel implements LanguageModel {
async doStream({ prompt }) {
// 调用 OpenAI 官方流式接口
const rawSSEStream = await fetchOpenAIStream(prompt)
// 关键:把 OpenAI 格式 → 统一格式
const standardStream = convertOpenAIStream(rawSSEStream)
// 返回统一流
return { stream: standardStream }
}
}
// =========================
// 转换器:厂商格式 → 标准格式(灵魂)
// =========================
async function* convertOpenAIStream(rawStream) {
for await (const chunk of rawStream) {
// 解析 OpenAI 自己的结构
const text = chunk.choices[0]?.delta?.content || ''
// 吐统一格式
yield { type: 'text-delta', textDelta: text }
}
}用户调用:完全不用管底层
async function uiDemo() {
const model = new OpenAIModel()
// 调用统一方法
const { stream } = await model.doStream({ prompt: '你好' })
// 消费统一流
for await (const part of stream) {
console.log(part.textDelta) // 打字机输出
}
}如何实现自己的 Mock Model
那么在 Vercel 的 AI core 我们实现一个自己的 Mock Model Provider 就要实现 LanguageModelV3 接口
specificationVersion版本号provider: 'mock'供应商modelId: 'mock-model'模型 IDget supportedUrls() Vercel AI SDK内部用的,告诉 SDK:这个模型支持哪些 “URL 模式”,要不要做 URL 安全校验。SDK 会问模型:你支持这个 URL 吗?模型通过supportedUrls回答:支持 / 不支持 / 支持哪些前缀supportedUrls: Promise.resolve({ allowedPrefixes: ['https://'], })doGenerate非流式对话接口 一次性把完整回答返回 ,不逐字打字。async doGenerate({ prompt }: any) { return { content: [{ type: 'text', text: pickResponse(prompt) }], finishReason: { unified: 'stop', raw: undefined }, usage: USAGE, warnings: [], }; }doStream流式输出接口 不一次性返回完整答案,而是一个字一个字推给前端(打字机效果)。因为这个用的最多,可以详细学一下
{ prompt }= 完整对话历史 和doGenerate一模一样。返回格式(V2 )
return { stream: ReadableStream<分片> };必须返回一个标准 Web ReadableStream。
流里面的「分片」是什么?(最重要)
text-start 告诉 SDK:文本开始了
{ type: 'text-start', id: 'text-1' }text-delta 每一个字
{ type: 'text-delta', id: 'text-1', delta: '你' } { type: 'text-delta', id: 'text-1', delta: '好' }text-end 告诉 SDK:文本发完了
{ type: 'text-end', id: 'text-1' }finish 最终结束,带 token 用量
{ type: 'finish', finishReason: { unified: 'stop' }, usage: { promptTokens: 10, completionTokens: 20 } }
只要实现了上面的接口方法,就可以实现我们自己的 Mock Model Provider 在 Vercel AI 中做 Mock 调用了!
export function createMockModel() {
return {
specificationVersion: 'v2',
provider: 'mock',
modelId: 'tiny-model',
get supportedUrls() {
return Promise.resolve({});
},
// 一次性返回
async doGenerate({ prompt }: any) {
return {
content: [{ type: 'text', text: '我是迷你 mock 模型' }],
finishReason: { unified: 'stop' },
usage: { promptTokens: 1, completionTokens: 1 },
warnings: [],
};
},
// 流式打字
async doStream({ prompt }: any) {
const chunks = [
{ type: 'text-start', id: '1' },
{ type: 'text-delta', id: '1', delta: '我' },
{ type: 'text-delta', id: '1', delta: '在' },
{ type: 'text-delta', id: '1', delta: '流' },
{ type: 'text-delta', id: '1', delta: '式' },
{ type: 'text-end', id: '1' },
{ type: 'finish', finishReason: { unified: 'stop' }, usage: {} },
];
return {
stream: new ReadableStream({
start(controller) {
chunks.forEach(chunk => controller.enqueue(chunk));
controller.close();
},
}),
};
},
};
}关于ReadableStream
ReadableStream 是 浏览器 / JS 标准的 “数据流管道”
可以随时给、慢慢给、异步给
适合:打字机、大文件下载、视频加载、SSE 流
你可以把它理解成:一根管子,你往里面一段一段塞数据,外面一点一点读。就是专门用来做流式输出的。
你要发一句话:我喜欢你
不用流:整句话一次性扔过去
用 ReadableStream:
塞一个字
我塞一个字
喜塞一个字
欢塞一个字
你关门结束
外面会按顺序收到每一个字 → 打字机效果
在你的 doStream 里,给 Vercel AI SDK 提供一个可以持续读取内容的流。
const stream = new ReadableStream({
start(controller) {
controller.enqueue("第1条");
controller.enqueue("第2条");
controller.enqueue("第3条");
controller.close();
},
});
const reader = stream.getReader();
reader.read().then(console.log);
// 输出:{ done: false, value: "第1条" }
reader.read().then(console.log);
// 输出:{ done: false, value: "第2条" }
reader.read().then(console.log);
// 输出:{ done: false, value: "第3条" }
reader.read().then(console.log);
// 输出:{ done: true, value: undefined }读取流 = 读一次,拿一个;读一次,拿一个。
用一下我们的Mock Model
import "dotenv/config";
import { streamText } from "ai";
import { createMockModel } from "./mock-model";
const model = createMockModel();
async function main() {
const result = await streamText({
model,
prompt: "用一句话介绍你自己",
});
for await (const chunk of result.textStream) {
process.stdout.write(chunk);
}
console.log("\n");
}
main();
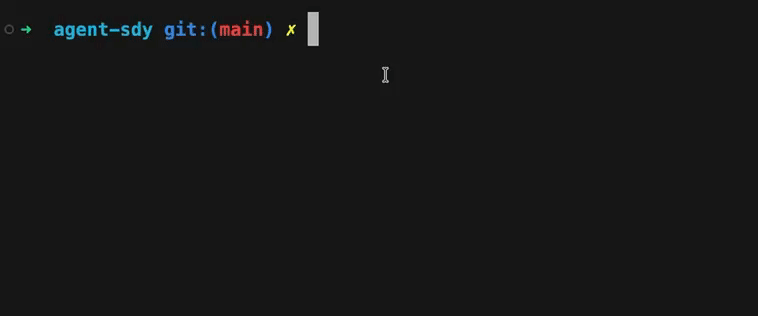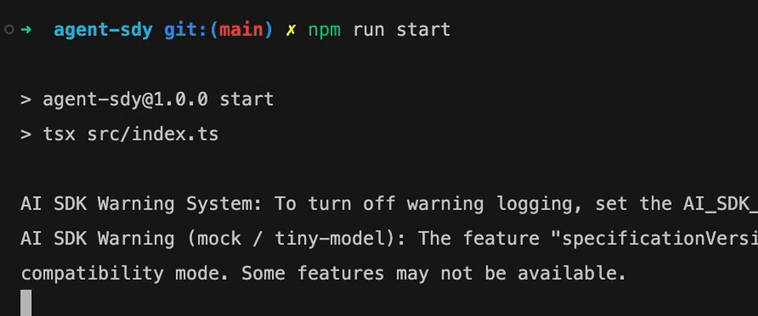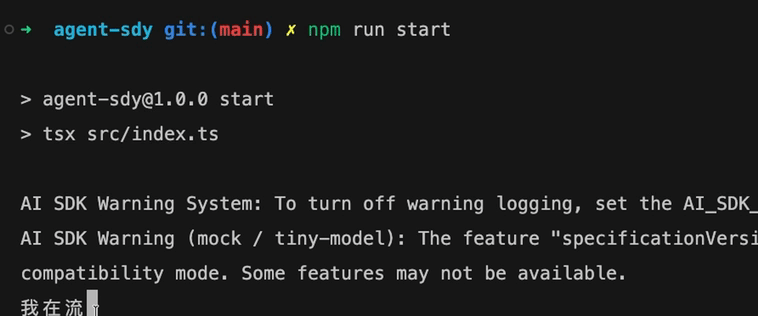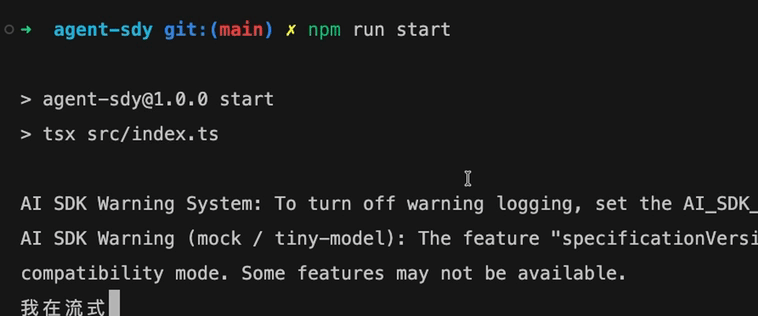
尝试运行一下
> agent-sdy@1.0.0 start
> tsx src/index.ts
AI SDK Warning System: To turn off warning logging, set the AI_SDK_LOG_WARNINGS global to false.
AI SDK Warning (mock / tiny-model): The feature "specificationVersion" is used in a compatibility mode. Using v2 specification compatibility mode. Some features may not be available.
我在流式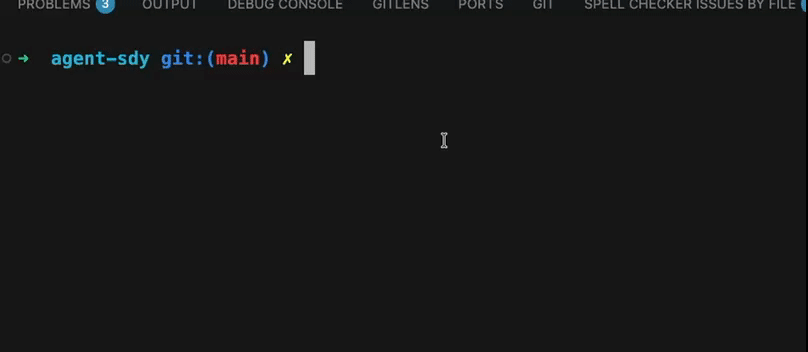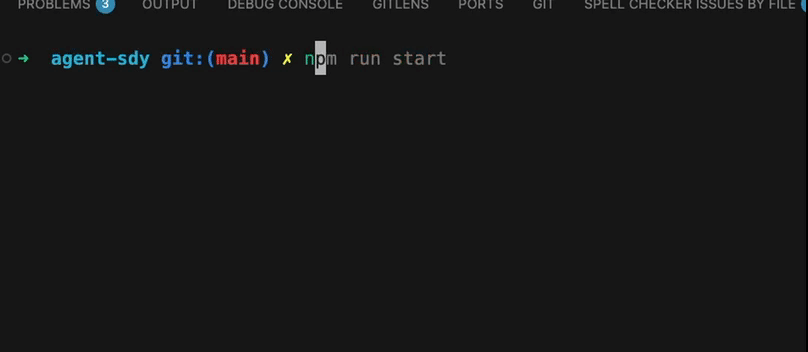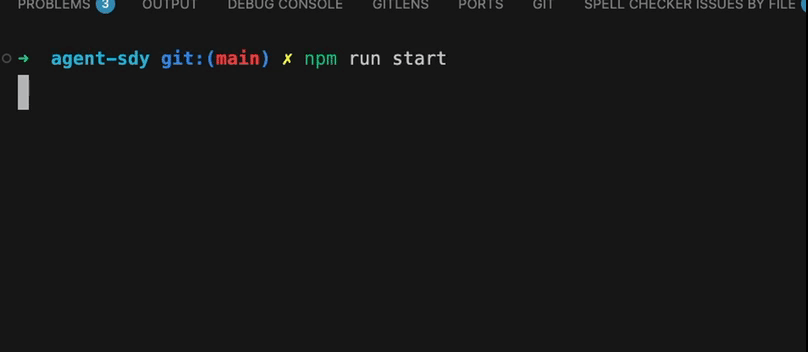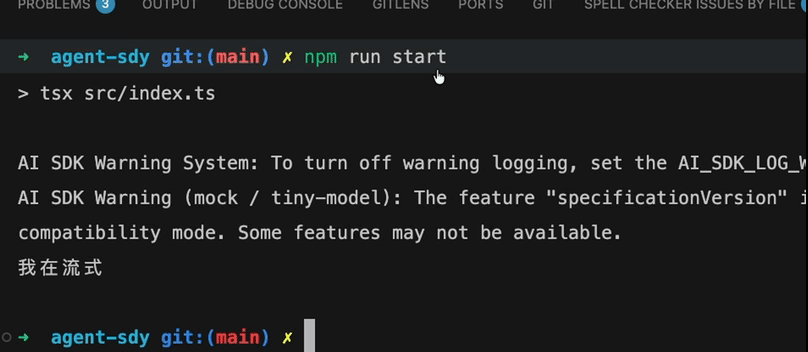
好像不是那种大模型的流式效果,因为我们写的 doStream 里面的 controller.enqueue(chunk) 在代码层面通过循环执行追加chunk,执行速度非常快!所以看不出流式的效果!
stream: new ReadableStream({
start(controller) {
chunks.forEach(chunk => controller.enqueue(chunk));
controller.close();
},
}),我们可以稍微改造一下这里的代码,每次controller.enqueue(chunk)后,等待一段时间去 enqueue 下一个chunk
stream: new ReadableStream({
start(controller) {
let index = 0;
function sendChunk() {
if (index < chunks.length) {
controller.enqueue(chunks[index++]);
// 延迟一秒递归调用!
setTimeout(sendChunk, 1000);
} else {
controller.close();
}
}
sendChunk();
},
}),
MockModel 的完整代码
src/mock-model/index.ts
export function createMockModel() {
return {
specificationVersion: "v2",
provider: "mock",
modelId: "tiny-model",
get supportedUrls() {
return Promise.resolve({});
},
// 一次性返回
async doGenerate({ prompt }: any) {
return {
content: [{ type: "text", text: "我是迷你 mock 模型" }],
finishReason: { unified: "stop" },
usage: { promptTokens: 1, completionTokens: 1 },
warnings: [],
};
},
// 流式打字
async doStream({ prompt }: any) {
const chunks = [
{ type: "text-start", id: "1" },
{ type: "text-delta", id: "1", delta: "我" },
{ type: "text-delta", id: "1", delta: "在" },
{ type: "text-delta", id: "1", delta: "流" },
{ type: "text-delta", id: "1", delta: "式" },
{ type: "text-end", id: "1" },
{ type: "finish", finishReason: { unified: "stop" }, usage: {} },
];
return {
stream: new ReadableStream({
start(controller) {
let index = 0;
function sendChunk() {
if (index < chunks.length) {
controller.enqueue(chunks[index++]);
setTimeout(sendChunk, 1000);
} else {
controller.close();
}
}
sendChunk();
},
}),
};
},
};
}
src/index.ts
import "dotenv/config";
import { streamText } from "ai";
import { createMockModel } from "./mock-model";
const model = createMockModel();
async function main() {
const result = await streamText({
model,
prompt: "用一句话介绍你自己",
});
for await (const chunk of result.textStream) {
process.stdout.write(chunk);
}
console.log("\n");
}
main();
把单纯的输出Model改造为可以持续对话
现在的Mock大模型,我们执行一次,通过 streamText 调用一次后,就没有然后了!
我们需要把它变成可以对话的,能记住和你的聊天记录的!
我们先在终端实现类似Cli 版本的可以对话的大模型!
所以我们要在代码里要增加两个东西:
支持用户输入!
readline// 创建 readline 实例 // createInterface 的 input 和 output 就是指定输入、输出的来源 / 去向,可以换成任意 ** 流(Stream)** 对象。比如 socket con等 const rl = createInterface({ input: process.stdin,// 数据从哪里来,这里是终端输入 → process.stdin output: process.stdout, // 数据写到哪里去,这里是终端输出 → process.stdout }); rl.question('\nYou: ', async (input) => { // 拿到用户输入的 input,执行异步逻辑(如调 AI 接口) });增加历史消息的记录!
Messages, 因为大模型本身是没有记忆的,所以我们每次对话,要把之前的上下文都要塞回去!const messages: ModelMessage[] = [];
下面是一个单纯使用 readline 实现一个写死的对话Demo,后续我们会把它一步步的改造为和mock Model对话(交互对话也是写死的),最终会和真实的大模型去对话!
import "dotenv/config";
import { createInterface } from "node:readline";
const r1 = createInterface({
input: process.stdin,
output: process.stdout,
});
function main() {
r1.question("\n User Say:", (input) => {
if (!input.trim() || input.trim().toLowerCase() === "bye") {
process.stdout.write("Assistant: Bye ");
// 延迟一点点关闭,让控制台把文字打出来
// 输出语句后马上r1.close(),缓冲还未落地就关闭流,文字直接消失
// 也可以直接用console代替,这个不受close的影响,肯定会执行完
setTimeout(() => {
r1.close();
}, 1000);
return;
}
if (input === "您好") {
process.stdout.write("Assistant说:");
process.stdout.write("Hi\n");
} else {
process.stdout.write("Assistant说:");
process.stdout.write("我还处理不了\n" + new Date().getTime());
}
main();
});
}
main();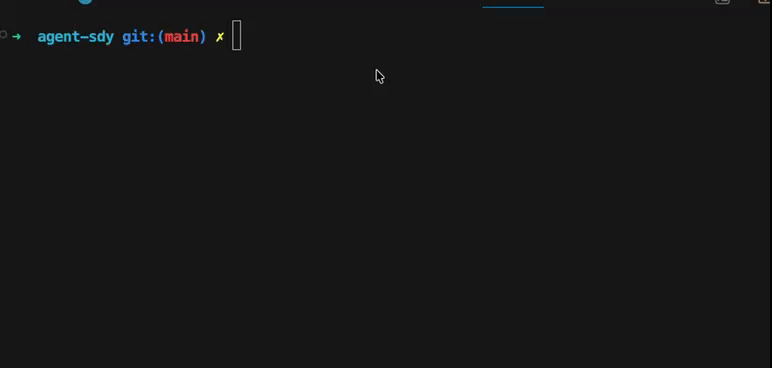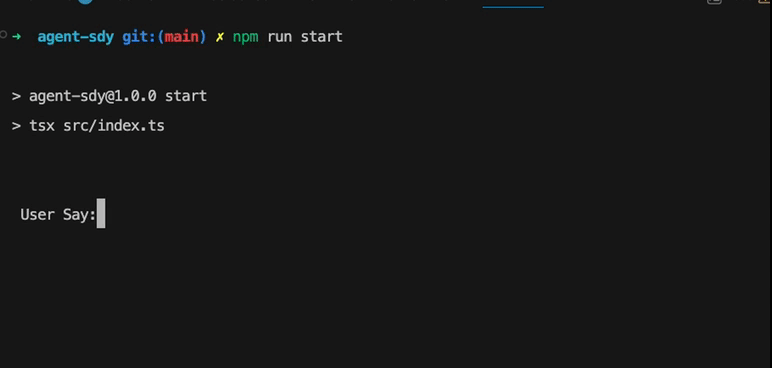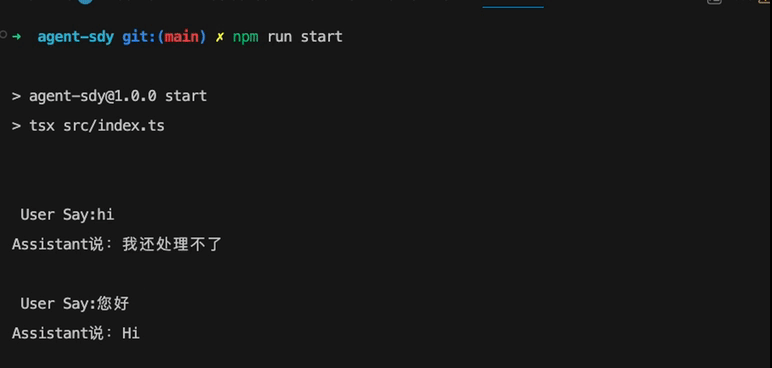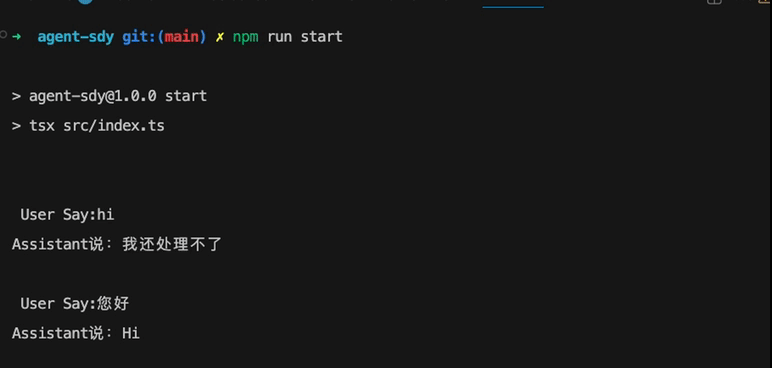
改造Mock Model支持固定对话交流!
首先先把调用的代码改造了,其实就是从固定的回复,改为输出大模型的回复!
然后增加了 ModelMessage 分角色存储好用户和大模型的对话记录!
import "dotenv/config";
import { createInterface } from "node:readline";
import { createMockModel } from "./mock-model";
import { ModelMessage, streamText } from "ai";
const model = createMockModel();
const r1 = createInterface({
input: process.stdin,
output: process.stdout,
});
const messages: ModelMessage[] = [];
function main() {
r1.question("\n User Say:", async (input) => {
if (!input.trim() || input.trim().toLowerCase() === "bye") {
process.stdout.write("Assistant: Bye ");
// 延迟一点点关闭,让控制台把文字打出来
// 输出语句后马上r1.close(),缓冲还未落地就关闭流,文字直接消失
// 也可以直接用console代替,这个不受close的影响,肯定会执行完
setTimeout(() => {
r1.close();
}, 1000);
return;
}
messages.push({ role: "user", content: input.trim() });
const result = await streamText({
model,
prompt: input.trim(), // 这里其实有问题 InvalidPromptError [AI_InvalidPromptError]: Invalid prompt: prompt and messages cannot be defined at the same time
messages,
});
let fullRep = "";
for await (const chunk of result.textStream) {
process.stdout.write(chunk);
fullRep += chunk;
}
messages.push({ role: "assistant", content: fullRep });
console.log("\n"); // 防止被覆盖
main();
});
}
main();
上面代码 prompt 和 messages 不能同时用,会报错的
message里面已经包含了最新的用户的prompt 两个参数只可以选一否则会报错
【
InvalidPromptError [AI_InvalidPromptError]: Invalid prompt: prompt and messages cannot be defined at the same time】
然后改造Mock Model,因为是模拟模型所以我们也定义了一些固定回复,只不过是放在了模拟模型的内部!
// 预设的固定回复
const FixedReply = new Map([
["你是谁", "我是规则驱动型Mock模拟模型,仅执行预设固定应答,无自主思考能力"],
["你是什么模型", "轻量化离线Mock测试模型,用于接口调试与流程模拟"],
["你的开发者", "内置预设规则封装模型,无独立开发主体定位"],
["你有什么能力", "仅响应固定话术、结构化模拟数据,不支持自由对话创作"],
["能不能联网", "禁用网络检索,仅使用本地静态预设规则响应"],
["现在几点", "固定测试时间:2026通用测试时区,无实时时间同步"],
["退出", "Mock会话结束,清空临时运行缓存"],
]);
// 根据输入匹配固定回复!
function reply(inputText: string) {
const defaultReply = "超出预设应答规则范围,无法进行自定义响应";
const text = inputText.trim();
return FixedReply.get(text) || defaultReply;
}然后我们对doStream的方法进行改造
async doStream({ prompt }: any) {
console.log("当前完整的prompt记录", JSON.stringify(prompt)); // 当前完整的prompt记录 [{"role":"user","content":[{"type":"text","text":"您好"}]},{"role":"assistant","content":[{"type":"text","text":"超出预设应答规则范围,无法进行自定义响应"}]},{"role":"user","content":[{"type":"text","text":"你是谁"}]}]
// 过滤出用户的消息,拿到最新的一条用户消息!其实如果传入了message,这里通常会传入全部的对话记录,所以要过滤出用户的记录先
const userMsgs = (prompt || []).filter((m: any) => m.role === "user");
const last = userMsgs[userMsgs.length - 1];
const text = (last?.content || [])
.map((c: any) => c.text || "")
.join("")
.toLowerCase();
// 获取固定回复
const replyResult = reply(text);
const chunks = [
{ type: "text-start", id: "1" },
// 分割成 text-delta chunk 每个字为一个chunk
...replyResult.split("").map((char: string) => ({
type: "text-delta",
id: "1",
delta: char,
})),
{ type: "text-end", id: "1" },
{ type: "finish", finishReason: { unified: "stop" }, usage: {} },
];
return {
stream: new ReadableStream({
start(controller) {
let index = 0;
function sendChunk() {
if (index < chunks.length) {
controller.enqueue(chunks[index++]);
setTimeout(sendChunk, 100);
} else {
controller.close();
}
}
sendChunk();
},
}),
};
},
可以对话的完整代码
src/mock-model/index.ts
const FixedReply = new Map([
["你是谁", "我是规则驱动型Mock模拟模型,仅执行预设固定应答,无自主思考能力"],
["你是什么模型", "轻量化离线Mock测试模型,用于接口调试与流程模拟"],
["你的开发者", "内置预设规则封装模型,无独立开发主体定位"],
["你有什么能力", "仅响应固定话术、结构化模拟数据,不支持自由对话创作"],
["能不能联网", "禁用网络检索,仅使用本地静态预设规则响应"],
["现在几点", "固定测试时间:2026通用测试时区,无实时时间同步"],
["退出", "Mock会话结束,清空临时运行缓存"],
]);
function reply(inputText: string) {
const defaultReply = "超出预设应答规则范围,无法进行自定义响应";
const text = inputText.trim();
return FixedReply.get(text) || defaultReply;
}
export function createMockModel() {
return {
specificationVersion: "v2",
provider: "mock",
modelId: "tiny-model",
get supportedUrls() {
return Promise.resolve({});
},
// 一次性返回
async doGenerate({ prompt }: any) {
return {
content: [{ type: "text", text: "我是迷你 mock 模型" }],
finishReason: { unified: "stop" },
usage: { promptTokens: 1, completionTokens: 1 },
warnings: [],
};
},
// 流式打字
async doStream({ prompt }: any) {
console.log("当前完整的prompt记录", JSON.stringify(prompt)); // [{"role":"user","content":[{"type":"text","text":"你是谁"}]}]
const userMsgs = (prompt || []).filter((m: any) => m.role === "user");
const last = userMsgs[userMsgs.length - 1];
const text = (last?.content || [])
.map((c: any) => c.text || "")
.join("")
.toLowerCase();
const replyResult = reply(text);
const chunks = [
{ type: "text-start", id: "1" },
...replyResult.split("").map((char: string) => ({
type: "text-delta",
id: "1",
delta: char,
})),
{ type: "text-end", id: "1" },
{ type: "finish", finishReason: { unified: "stop" }, usage: {} },
];
return {
stream: new ReadableStream({
start(controller) {
let index = 0;
function sendChunk() {
if (index < chunks.length) {
controller.enqueue(chunks[index++]);
setTimeout(sendChunk, 100);
} else {
controller.close();
}
}
sendChunk();
},
}),
};
},
};
}src/index.ts调用代码
import "dotenv/config";
import { createInterface } from "node:readline";
import { createMockModel } from "./mock-model";
import { ModelMessage, streamText } from "ai";
const model = createMockModel();
const r1 = createInterface({
input: process.stdin,
output: process.stdout,
});
const messages: ModelMessage[] = [];
function main() {
r1.question("\n User Say:", async (input) => {
if (!input.trim() || input.trim().toLowerCase() === "bye") {
process.stdout.write("Assistant: Bye ");
// 延迟一点点关闭,让控制台把文字打出来
// 输出语句后马上r1.close(),缓冲还未落地就关闭流,文字直接消失
// 也可以直接用console代替,这个不受close的影响,肯定会执行完
setTimeout(() => {
r1.close();
}, 1000);
return;
}
messages.push({ role: "user", content: input.trim() });
const result = await streamText({
model,
messages,
});
let fullRep = "";
for await (const chunk of result.textStream) {
process.stdout.write(chunk);
fullRep += chunk;
}
messages.push({ role: "assistant", content: fullRep });
console.log("\n"); // 防止被覆盖
main();
});
}
main();执行效果:可以看到回复都是按照固定回复的,然后message也都被保存了下来!
src/mock-model/index.ts
const FixedReply = new Map([
["你是谁", "我是规则驱动型Mock模拟模型,仅执行预设固定应答,无自主思考能力"],
["你是什么模型", "轻量化离线Mock测试模型,用于接口调试与流程模拟"],
["你的开发者", "内置预设规则封装模型,无独立开发主体定位"],
["你有什么能力", "仅响应固定话术、结构化模拟数据,不支持自由对话创作"],
["能不能联网", "禁用网络检索,仅使用本地静态预设规则响应"],
["现在几点", "固定测试时间:2026通用测试时区,无实时时间同步"],
["退出", "Mock会话结束,清空临时运行缓存"],
]);
function reply(inputText: string) {
const defaultReply = "超出预设应答规则范围,无法进行自定义响应";
const text = inputText.trim();
return FixedReply.get(text) || defaultReply;
}
export function createMockModel() {
return {
specificationVersion: "v2",
provider: "mock",
modelId: "tiny-model",
get supportedUrls() {
return Promise.resolve({});
},
// 一次性返回
async doGenerate({ prompt }: any) {
return {
content: [{ type: "text", text: "我是迷你 mock 模型" }],
finishReason: { unified: "stop" },
usage: { promptTokens: 1, completionTokens: 1 },
warnings: [],
};
},
// 流式打字
async doStream({ prompt }: any) {
console.log("当前完整的prompt记录", JSON.stringify(prompt)); // [{"role":"user","content":[{"type":"text","text":"你是谁"}]}]
const userMsgs = (prompt || []).filter((m: any) => m.role === "user");
const last = userMsgs[userMsgs.length - 1];
const text = (last?.content || [])
.map((c: any) => c.text || "")
.join("")
.toLowerCase();
const replyResult = reply(text);
const chunks = [
{ type: "text-start", id: "1" },
...replyResult.split("").map((char: string) => ({
type: "text-delta",
id: "1",
delta: char,
})),
{ type: "text-end", id: "1" },
{ type: "finish", finishReason: { unified: "stop" }, usage: {} },
];
return {
stream: new ReadableStream({
start(controller) {
let index = 0;
function sendChunk() {
if (index < chunks.length) {
controller.enqueue(chunks[index++]);
setTimeout(sendChunk, 100);
} else {
controller.close();
}
}
sendChunk();
},
}),
};
},
};
}src/index.ts调用代码
import "dotenv/config";
import { createInterface } from "node:readline";
import { createMockModel } from "./mock-model";
import { ModelMessage, streamText } from "ai";
const model = createMockModel();
const r1 = createInterface({
input: process.stdin,
output: process.stdout,
});
const messages: ModelMessage[] = [];
function main() {
r1.question("\n User Say:", async (input) => {
if (!input.trim() || input.trim().toLowerCase() === "bye") {
process.stdout.write("Assistant: Bye ");
// 延迟一点点关闭,让控制台把文字打出来
// 输出语句后马上r1.close(),缓冲还未落地就关闭流,文字直接消失
// 也可以直接用console代替,这个不受close的影响,肯定会执行完
setTimeout(() => {
r1.close();
}, 1000);
return;
}
messages.push({ role: "user", content: input.trim() });
const result = await streamText({
model,
messages,
});
let fullRep = "";
for await (const chunk of result.textStream) {
process.stdout.write(chunk);
fullRep += chunk;
}
messages.push({ role: "assistant", content: fullRep });
console.log("\n"); // 防止被覆盖
main();
});
}
main();执行效果:可以看到回复都是按照固定回复的,然后message也都被保存了下来!
src/mock-model/index.ts
const FixedReply = new Map([
["你是谁", "我是规则驱动型Mock模拟模型,仅执行预设固定应答,无自主思考能力"],
["你是什么模型", "轻量化离线Mock测试模型,用于接口调试与流程模拟"],
["你的开发者", "内置预设规则封装模型,无独立开发主体定位"],
["你有什么能力", "仅响应固定话术、结构化模拟数据,不支持自由对话创作"],
["能不能联网", "禁用网络检索,仅使用本地静态预设规则响应"],
["现在几点", "固定测试时间:2026通用测试时区,无实时时间同步"],
["退出", "Mock会话结束,清空临时运行缓存"],
]);
function reply(inputText: string) {
const defaultReply = "超出预设应答规则范围,无法进行自定义响应";
const text = inputText.trim();
return FixedReply.get(text) || defaultReply;
}
export function createMockModel() {
return {
specificationVersion: "v2",
provider: "mock",
modelId: "tiny-model",
get supportedUrls() {
return Promise.resolve({});
},
// 一次性返回
async doGenerate({ prompt }: any) {
return {
content: [{ type: "text", text: "我是迷你 mock 模型" }],
finishReason: { unified: "stop" },
usage: { promptTokens: 1, completionTokens: 1 },
warnings: [],
};
},
// 流式打字
async doStream({ prompt }: any) {
console.log("当前完整的prompt记录", JSON.stringify(prompt)); // [{"role":"user","content":[{"type":"text","text":"你是谁"}]}]
const userMsgs = (prompt || []).filter((m: any) => m.role === "user");
const last = userMsgs[userMsgs.length - 1];
const text = (last?.content || [])
.map((c: any) => c.text || "")
.join("")
.toLowerCase();
const replyResult = reply(text);
const chunks = [
{ type: "text-start", id: "1" },
...replyResult.split("").map((char: string) => ({
type: "text-delta",
id: "1",
delta: char,
})),
{ type: "text-end", id: "1" },
{ type: "finish", finishReason: { unified: "stop" }, usage: {} },
];
return {
stream: new ReadableStream({
start(controller) {
let index = 0;
function sendChunk() {
if (index < chunks.length) {
controller.enqueue(chunks[index++]);
setTimeout(sendChunk, 100);
} else {
controller.close();
}
}
sendChunk();
},
}),
};
},
};
}src/index.ts调用代码
import "dotenv/config";
import { createInterface } from "node:readline";
import { createMockModel } from "./mock-model";
import { ModelMessage, streamText } from "ai";
const model = createMockModel();
const r1 = createInterface({
input: process.stdin,
output: process.stdout,
});
const messages: ModelMessage[] = [];
function main() {
r1.question("\n User Say:", async (input) => {
if (!input.trim() || input.trim().toLowerCase() === "bye") {
process.stdout.write("Assistant: Bye ");
// 延迟一点点关闭,让控制台把文字打出来
// 输出语句后马上r1.close(),缓冲还未落地就关闭流,文字直接消失
// 也可以直接用console代替,这个不受close的影响,肯定会执行完
setTimeout(() => {
r1.close();
}, 1000);
return;
}
messages.push({ role: "user", content: input.trim() });
const result = await streamText({
model,
messages,
});
let fullRep = "";
for await (const chunk of result.textStream) {
process.stdout.write(chunk);
fullRep += chunk;
}
messages.push({ role: "assistant", content: fullRep });
console.log("\n"); // 防止被覆盖
main();
});
}
main();执行效果:可以看到回复都是按照固定回复的,然后message也都被保存了下来!
也可以顺手把 doGenerate 改造了 都是一样的逻辑!
// 一次性返回
async doGenerate({ prompt }: any) {
console.log("当前完整的prompt记录", JSON.stringify(prompt)); // [{"role":"user","content":[{"type":"text","text":"你是谁"}]}]
const userMsgs = (prompt || []).filter((m: any) => m.role === "user");
const last = userMsgs[userMsgs.length - 1];
const text = (last?.content || [])
.map((c: any) => c.text || "")
.join("")
.toLowerCase();
const replyResult = reply(text);
return {
content: [{ type: "text", text: replyResult }],
finishReason: { unified: "stop" },
usage: { promptTokens: 1, completionTokens: 1 },
warnings: [],
};
},const { text } = await generateText({
model,
messages,
});
process.stdout.write(text);
messages.push({ role: "assistant", content: text });
console.log("\n"); // 防止被覆盖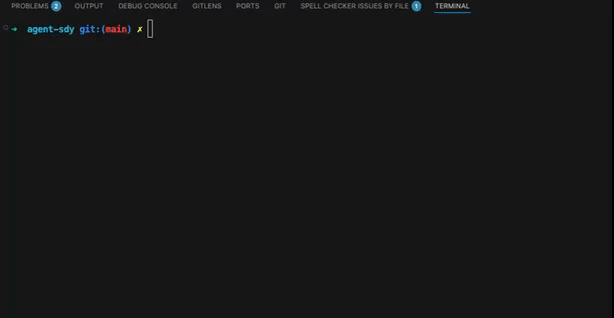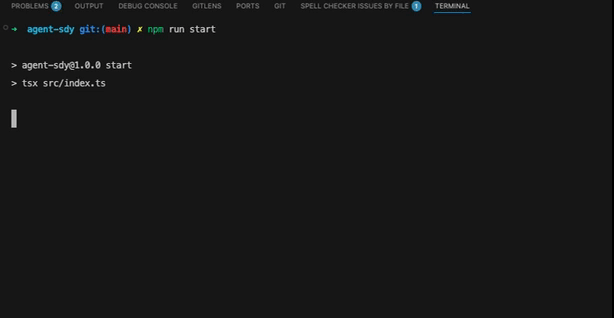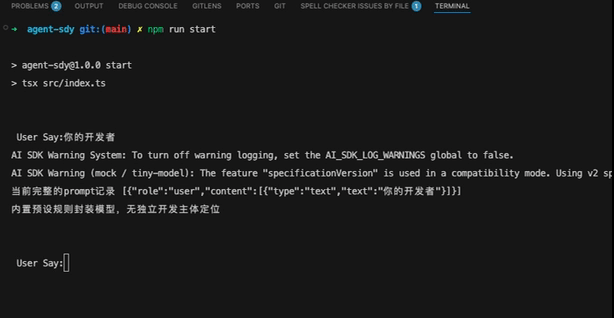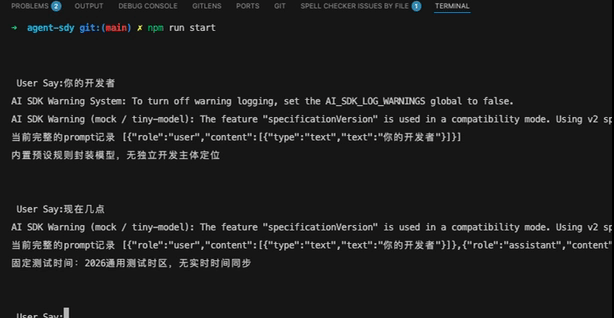
当然因为是本地,基本都是秒回复了!
无缝接入真实大模型
Mock Model的初心就我们能自由本地控制大模型输出方便调试,同样也能无缝的切换为真实的大模型!
我们下一步就来看看,我们能不能无缝的切换过去!
这里我用Qwen的大模型
之前我们安装了 dotenv 负责从 .env 文件加载环境变量
在项目目录创建 .env 文件
OPENAI_API_KEY=你的key然后把Mock Model 替换为 qwen.chat('qwen-plus-latest')就OK了 (qwen-plus-latest 你也可以换成其他你想用的模型ID)
const model = createOpenAI({
baseURL: "https://dashscope.aliyuncs.com/compatible-mode/v1",
apiKey: process.env.DASHSCOPE_API_KEY,
}).chat('qwen-plus-latest')然后我们来测试是否成功:
是否可以反复对话
并且可以保留我们对话的上下文

可以看到,很完美!
到这里,我们不仅实现了cli 版本的和大模型对话,也有上下文的功能!
还确保了Mock Model和 真实大模型的无缝切换
CallBack 如果后面我们在开发的过程中,一些场景无法根据真实的大模型去调试【比如大模型不同的状态报错,tools反复调用幻觉失败等场景】,我们也完全有能力从Mock的大模型来进行扩展开发,模拟大模型的报错返回场景,保证我们Agent的稳定性!