面对众多的工具Tools怎么样合理的注册
现在我们的 Agent 只有两个玩具工具(天气和计算器),面对真实任务完全无能为力。
更大的问题是,就算你想加 10 个工具,现在的代码结构也不支持。
工具定义散落在 tools.ts 里,和 Agent Loop 耦合在一起,没有统一的注册、没有结果管理。
比如我们在引入一个读文件的工具!read_file
一个工具返回 10 万字符的文件内容,直接塞进上下文——一次调用就能把你的 token 预算吃掉一半。
所以我们需要搭一个正经的工具系统,从注册到执行到截断上下文,每一层都有明确的职责。
1. 强化Tools
之前定义的模型只包含了三样东西
- 一段描述——告诉模型"这个工具干什么、什么时候该用"
- 一份参数 Schema——告诉模型"调用时需要传什么参数、什么类型"
- 一个执行函数——真正干活的代码
但在生产环境里,光有这三样不够。你还需要知道:
- 这个工具能不能和别的工具并行执行?【比如一边在写文件,那么另一边能不能同时读这个写的文件,这样就造成了不一致的问题】
- 它是只读的还是会修改系统状态?
- 它的返回结果最大有多长?【比如用户让agent读了一片几十万字的文章,有些模型的上下文直接撑爆了】
所以我们定义的工具接口长这样:
interface ToolDefinition {
name: string;
description: string; // 给模型看的描述
parameters: Record<string, unknown>; // JSON Schema
// 元数据——给 Agent Loop 做决策用
isConcurrencySafe?: boolean; // 能否并行
isReadOnly?: boolean; // 是否只读
maxResultChars?: number; // 结果最大长度
execute: (input: any) => Promise<unknown>;
}
前三个字段是模型需要的
模型只需要知道在什么场景下根据描述匹配合适的工具,然后生成正确的参数交给tool 去执行
后三个状态值是 execute 执行需要的。
我们需要在execute把控好工具的调用参数,通过状态管理工具的调用机制,做好上下文控制!
execute中根据上面的状态值来控制当前工具的执行时机,队列控制等!
那我们定义新的读写工具就是:
import { readFileSync, writeFileSync, readdirSync, statSync } from 'node:fs';
import { join, resolve } from 'node:path';
import type { ToolDefinition } from './tool-register';
export const weatherTool: ToolDefinition = {
name: 'get_weather',
description: '查询指定城市的天气信息',
parameters: {
type: 'object',
properties: {
city: { type: 'string', description: '城市名称,如"北京"、"上海"' },
},
required: ['city'],
additionalProperties: false,
},
isConcurrencySafe: true,
isReadOnly: true,
execute: async ({ city }: { city: string }) => {
const data: Record<string, string> = {
'北京': '晴,15-25°C,东南风 2 级',
'上海': '多云,18-22°C,西南风 3 级',
'深圳': '阵雨,22-28°C,南风 2 级',
'广州': '多云转晴,20-28°C,东风 3 级',
'杭州': '晴,14-24°C,北风 2 级',
'成都': '阴,16-22°C,微风',
};
return data[city] || `${city}:暂无数据`;
},
};
export const calculatorTool: ToolDefinition = {
name: 'calculator',
description: '计算数学表达式的结果。当用户提问涉及数学运算时使用',
parameters: {
type: 'object',
properties: {
expression: { type: 'string', description: '数学表达式,如 "2 + 3 * 4"' },
},
required: ['expression'],
additionalProperties: false,
},
isConcurrencySafe: true,
isReadOnly: true,
execute: async ({ expression }: { expression: string }) => {
try {
const result = new Function(`return ${expression}`)();
return `${expression} = ${result}`;
} catch {
return `无法计算: ${expression}`;
}
},
};
export const readFileTool: ToolDefinition = {
name: 'read_file',
description: '读取指定路径的文件内容',
parameters: {
type: 'object',
properties: {
path: { type: 'string', description: '文件路径' },
},
required: ['path'],
additionalProperties: false,
},
isConcurrencySafe: true,
isReadOnly: true,
maxResultChars: 500,
execute: async ({ path }: { path: string }) => {
const resolved = resolve(path);
return readFileSync(resolved, 'utf-8');
},
};
export const writeFileTool: ToolDefinition = {
name: 'write_file',
description: '写入内容到指定文件。如果文件已存在则覆盖',
parameters: {
type: 'object',
properties: {
path: { type: 'string', description: '文件路径' },
content: { type: 'string', description: '要写入的内容' },
},
required: ['path', 'content'],
additionalProperties: false,
},
isConcurrencySafe: false,
isReadOnly: false,
execute: async ({ path, content }: { path: string; content: string }) => {
const resolved = resolve(path);
writeFileSync(resolved, content, 'utf-8');
return `已写入 ${content.length} 字符到 ${path}`;
},
};
export const listDirectoryTool: ToolDefinition = {
name: 'list_directory',
description: '列出指定目录下的文件和子目录',
parameters: {
type: 'object',
properties: {
path: { type: 'string', description: '目录路径,默认为当前目录' },
},
required: [],
additionalProperties: false,
},
isConcurrencySafe: true,
isReadOnly: true,
execute: async ({ path = '.' }: { path?: string }) => {
const resolved = resolve(path);
const entries = readdirSync(resolved);
return entries.map(name => {
try {
const stat = statSync(join(resolved, name));
return `${stat.isDirectory() ? '[DIR]' : '[FILE]'} ${name}`;
} catch {
return `[?] ${name}`;
}
}).join('\n');
},
};
export const allTools: ToolDefinition[] = [
weatherTool,
calculatorTool,
readFileTool,
writeFileTool,
listDirectoryTool,
];
每个工具除了 execute 之外,都带了 isConcurrencySafe 和 isReadOnly 元数据。
read_file 是只读的,可以和其他只读工具并行;
write_file 有副作用,必须独占执行。
并发安全性不是按工具名决定的,而是按行为决定的。 同一个 bash 工具,ls 是只读的可以并发,rm -rf 就必须串行。
另外注意
readFileTool的maxResultChars: 500——这里故意设低了方便演示截断效果。生产环境通常设 50000 甚至更高。这就是为什么 Anthropic 在 Context Engineering 博客 里把「工具结果管理」列为 Agent 开发的核心挑战之一。
2. 搭建 ToolRegistry
有了统一接口,下一步是给工具找个"家"。ToolRegistry 做三件事:注册工具、查找工具、转换成 AI SDK 需要的格式。
import { jsonSchema } from 'ai';
/**
* 工具定义接口(AI 调用工具的标准结构)
* 所有文件读写、目录操作等工具都必须遵循这个接口
*/
export interface ToolDefinition {
name: string; // 工具唯一名称(如 read_file)
description: string; // 工具描述,用于 AI 理解功能
parameters: Record<string, unknown>; // 参数定义(JSON Schema 格式)
isConcurrencySafe?: boolean; // 是否并发安全:读安全,写不安全
isReadOnly?: boolean; // 是否只读:读文件/目录是只读,写不是
maxResultChars?: number; // 结果最大字符数,防止返回内容过长
execute: (input: any) => Promise<unknown>; // 工具执行函数(异步)
}
/**
* 默认最大返回字符数(未配置时使用)
*/
const DEFAULT_MAX_RESULT_CHARS = 3000;
/**
* 工具注册器
* 作用:统一管理、存储、查询所有 AI 工具
* 提供注册、获取、转 AI SDK 格式等能力
*/
export class ToolRegistry {
// 内部用 Map 存储所有工具:key=工具名,value=工具定义
private tools = new Map<string, ToolDefinition>();
/**
* 注册一个或多个工具
* @param tools 工具列表
*/
register(...tools: ToolDefinition[]): void {
for (const tool of tools) {
this.tools.set(tool.name, tool);
}
}
/**
* 根据工具名称获取工具
* @param name 工具名
* @returns 工具定义 或 undefined
*/
get(name: string): ToolDefinition | undefined {
return this.tools.get(name);
}
/**
* 获取所有已注册的工具
* @returns ToolDefinition[]
*/
getAll(): ToolDefinition[] {
return Array.from(this.tools.values());
}
/**
* 转换为 Vercel AI SDK 支持的工具格式
* 这是核心方法:把自定义工具 → AI 可调用的标准格式
* 自动包装执行逻辑 + 自动截断超长返回内容
*/
toAISDKFormat(): Record<string, any> {
const result: Record<string, any> = {};
for (const [name, tool] of this.tools) {
const maxChars = tool.maxResultChars;
const executeFn = tool.execute;
// 构建 AI SDK 标准工具结构
result[name] = {
description: tool.description,
inputSchema: jsonSchema(tool.parameters as any), // 转为 AI SDK 需要的 schema
execute: async (input: any) => {
// 1. 执行原工具逻辑
const raw = await executeFn(input);
// 2. 统一转为字符串(非字符串则格式化 JSON)
const text = typeof raw === 'string' ? raw : JSON.stringify(raw, null, 2);
// 3. 截断超长内容,避免 token 爆炸
return truncateResult(text, maxChars);
},
};
}
return result;
}
}
/**
* 截断超长文本(中间省略,保留前后关键内容)
* 避免 AI 收到过长内容导致 token 超限、响应变慢
*
* 策略:前 60% + 省略提示 + 后 40%
*
* @param text 原始文本
* @param maxChars 最大允许长度
* @returns 截断后的文本
*/
export function truncateResult(text: string, maxChars: number = DEFAULT_MAX_RESULT_CHARS): string {
// 长度没超限,直接返回
if (text.length <= maxChars) return text;
// 计算前后保留长度
const headSize = Math.floor(maxChars * 0.6);
const tailSize = maxChars - headSize;
// 截取前后内容
const head = text.slice(0, headSize);
const tail = text.slice(-tailSize);
// 计算省略了多少字符
const dropped = text.length - headSize - tailSize;
// 拼接最终结果
return `${head}\n\n... [省略 ${dropped} 字符] ...\n\n${tail}`;
}
其实上面的代码逻辑都很简单的!
-
register支持批量注册,传入ToolDefinition 数组 循环set到类内部的tools Map -
get / get ALL查询单个tool / 查回全部的tool -
toAISDKFormat内部map存储的tool 批量转换成Vercel SDK 需要的格式-
这样容易处理的好处是我们可以批量处理一些通用逻辑,比如说 ‘截断超长文本’ 这种功能!其实最终组装传递过去的和之前没什么区别。 工具注册一次,AI SDK 拿到的就是已经包含截断保护的版本。Agent Loop 不需要关心截断细节——ToolRegistry 帮你兜底了。
-
-
truncateResult自动做 Head/Tail 60/40 分割——保留前 60%(文件头部的标题和开头内容)和后 40%(文件末尾的最佳实践),中间用[省略 N 字符]标记。为什么是 60/40 而不是 100/0(只保留头部)?因为很多时候文件尾部的信息比中间更有价值
截断看起来是个小功能,但它直接决定了 Agent 能走多远。没有截断的 Agent,一次
read_file返回 5 万字符,上下文窗口直接被吃掉一大半。后面的推理、工具调用全部挤在剩余空间里,质量断崖式下降。
然后在外部注册使用即可(引入tools 注册 ,然后 tools.toAISDKFormat() 拼装好vercel SDK 传递给大模型调用!)
import { allTools } from "./tools/utility-tools";
const tools = new ToolRegistry()
tools.register(...allTools)
// ...其他代码...
while (current < maxLoop) {
let hasToolCall = false; // 判断本轮是否有工具调用
for (let attempt = 0; ; attempt++) {
// 核心,每次循环都会调用,根据这个结果判断还是否会有下次循环
try {
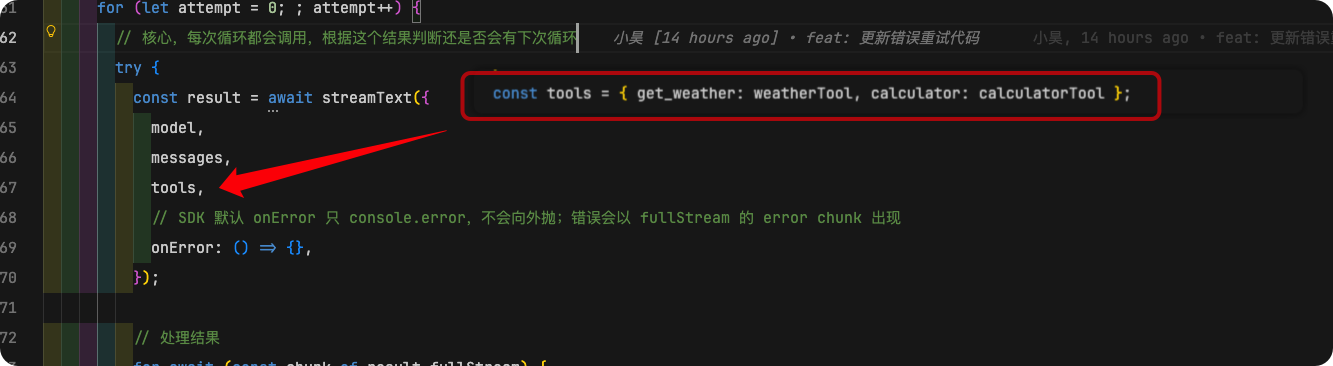
const result = await streamText({
model,
messages,
tools:tools.toAISDKFormat(),
// SDK 默认 onError 只 console.error,不会向外抛;错误会以 fullStream 的 error chunk 出现
onError: () => {},
});
我们来试一下,Tools 有没有生效,包括一些截断有没有生效!看下下面的执行!
╰─ npm run start
> agent-sdy@1.0.0 start
> tsx src/index.ts
You: 查看这个文件的内容'/Users/cunwangbro/agent-sdy/agent-markdown/1.如何写一个 Vercel SDK 的 Mock Mdoel.md'
【==================================开始Loop_1_==================================】
正在调用工具read_file call_6821d2f4f26443b6ab1713
【==================================看来还需要多一轮,来处理本轮"read_file"的调用结果==================================】
call_6821d2f4f26443b6ab1713
【==================================调用工具结果# 如何写一个 Vercel SDK 的 Mock Mdoel
[toc]
## Vercel AI的 适配器设计模式
我发现最近在学习大模型的 `agent` 的开发的时候呢
很多异常场景其实没办法完全通过真实的大模型复现
比如说 `tools` 的循环调用,API 的 429 等异常场景,不能很好的通过真实大模型去复现测试!
所以再开发的环境下,写一个 `MockModel`,让我们去 Mock 各种异常的场景还是很有必要的!
```shell
pnpm add ai @ai-sdk/openai dotenv
pnpm add -D typescript tsx @type
... [省略 18840 字符] ...
可以看到,很完美!
到这里,我们不仅实现了cli 版本的和大模型对话,也有上下文的功能!
还确保了Mock Model和 真实大模型的无缝切换,CallBack 如果后面我们在开发的过程中,一些场景无法根据真实的大模型去调试【比如大模型不同的状态报错,tools反复调用幻觉失败等场景】,我们也完全有能力从Mock的大模型来进行开发,模拟大模型的报错返回场景,保证我们Agent的稳定性!
==================================】
【==================================结束Loop1==================================】
581/15000
🚀🚀🚀🚀🚀🚀🚀🚀🚀🚀🚀当前step的全部信息: {"id":"chatcmpl-dd62a5b3-0b01-9478-a872-0185f9530c57","timestamp":"2026-05-27T06:44:34.000Z","modelId":"qwen-plus-latest","headers":{"content-type":"text/event-stream;charset=utf-8","date":"Wed, 27 May 2026 06:44:35 GMT","req-arrive-time":"1779864274850","req-cost-time":"718","resp-start-time":"1779864275568","server":"istio-envoy","transfer-encoding":"chunked","vary":"Origin","x-dashscope-call-gateway":"true","x-envoy-upstream-service-time":"718","x-request-id":"dd62a5b3-0b01-9478-a872-0185f9530c57"},"messages":[{"role":"assistant","content":[{"type":"tool-call","toolCallId":"call_6821d2f4f26443b6ab1713","toolName":"read_file","input":{"path":"/Users/cunwangbro/agent-sdy/agent-markdown/1.如何写一个 Vercel SDK 的 Mock Mdoel.md"}}]},{"role":"tool","content":[{"type":"tool-result","toolCallId":"call_6821d2f4f26443b6ab1713","toolName":"read_file","output":{"type":"text","value":"# 如何写一个 Vercel SDK 的 Mock Mdoel\n\n[toc]\n\n## Vercel AI的 适配器设计模式\n\n我发现最近在学习大模型的 `agent` 的开发的时候呢\n\n很多异常场景其实没办法完全通过真实的大模型复现\n\n比如说 `tools` 的循环调用,API 的 429 等异常场景,不能很好的通过真实大模型去复现测试!\n\n所以再开发的环境下,写一个 `MockModel`,让我们去 Mock 各种异常的场景还是很有必要的!\n\n```shell\npnpm add ai @ai-sdk/openai dotenv\npnpm add -D typescript tsx @type\n\n... [省略 18840 字符] ...\n\n\n\n\n可以看到,很完美!\n\n到这里,我们不仅实现了cli 版本的和大模型对话,也有上下文的功能!\n\n还确保了Mock Model和 真实大模型的无缝切换,CallBack 如果后面我们在开发的过程中,一些场景无法根据真实的大模型去调试【比如大模型不同的状态报错,tools反复调用幻觉失败等场景】,我们也完全有能力从Mock的大模型来进行开发,模拟大模型的报错返回场景,保证我们Agent的稳定性!\n"}}]}]}
【==================================开始Loop_2_==================================】
文件 `/Users/cunwangbro/agent-sdy/agent-markdown/1.如何写一个 Vercel SDK 的 Mock Mdoel.md` 的内容已成功读取,主要内容是关于如何编写一个 Vercel SDK 的 Mock Model,用于在开发环境中模拟大模型(如 AI Agent)的各种异常场景(例如工具循环调用、API 限流 429 错误等),以提升测试覆盖率和 Agent 稳定性。文中还提到了适配器设计模式、依赖安装(如 `ai`, `@ai-sdk/openai`, `dotenv` 等)、CLI 对话实现、上下文支持,以及 Mock Model 与真实模型的无缝切换能力。
如需进一步分析该文档(例如提取代码片段、总结关键步骤、生成示例 Mock 实现、或将其转换为其他格式),请随时告诉我!
【==================================结束Loop2==================================】
1620/15000
🚀🚀🚀🚀🚀🚀🚀🚀🚀🚀🚀当前step的全部信息: {"id":"chatcmpl-84d2c53f-a8f5-9016-bb18-d254962fbb54","timestamp":"2026-05-27T06:44:36.000Z","modelId":"qwen-plus-latest","headers":{"content-type":"text/event-stream;charset=utf-8","date":"Wed, 27 May 2026 06:44:36 GMT","req-arrive-time":"1779864276478","req-cost-time":"385","resp-start-time":"1779864276863","server":"istio-envoy","transfer-encoding":"chunked","vary":"Origin","x-dashscope-call-gateway":"true","x-envoy-upstream-service-time":"385","x-request-id":"84d2c53f-a8f5-9016-bb18-d254962fbb54"},"messages":[{"role":"assistant","content":[{"type":"text","text":"文件 `/Users/cunwangbro/agent-sdy/agent-markdown/1.如何写一个 Vercel SDK 的 Mock Mdoel.md` 的内容已成功读取,主要内容是关于如何编写一个 Vercel SDK 的 Mock Model,用于在开发环境中模拟大模型(如 AI Agent)的各种异常场景(例如工具循环调用、API 限流 429 错误等),以提升测试覆盖率和 Agent 稳定性。文中还提到了适配器设计模式、依赖安装(如 `ai`, `@ai-sdk/openai`, `dotenv` 等)、CLI 对话实现、上下文支持,以及 Mock Model 与真实模型的无缝切换能力。\n\n如需进一步分析该文档(例如提取代码片段、总结关键步骤、生成示例 Mock 实现、或将其转换为其他格式),请随时告诉我!"}]}]}
You:
可以看到我们完美的调用了read_file tools 并且对超大的内容做了阶段处理!

3. 并发控制:读写锁模式
AI 大模型有一个非常重要的能力:并行调用多个工具。当模型在一次回复里调用多个工具时,AI SDK 会并发执行所有带 execute 的工具。
比如它可以同时调用 "查北京天气"、"查上海天气"、"查广州天气" 三个工具,一次性获取所有数据。
但不是所有工具都能随便并行:
一个 write_file 和一个 read_file 同时跑,就可能出问题——你还没写完文件,另一个工具就开始读了。
之前在 ToolDefinition 留了个 isConcurrencySafe 字段一直没用,现在派上用场。
基本思路是经典的读写锁,让读工具随便并行,写工具必须独占:
- 只读工具(
isConcurrencySafe: true)→ 获取共享锁,可以和其他只读工具同时持有 - 读写工具(
isConcurrencySafe: false)→ 获取独占锁,必须等所有其他工具执行完才能开始
升级 tool-registry.ts,在锁字段、锁方法、toAISDKFormat() 的 execute 包装层三处加上锁逻辑:
锁的灵魂:三个核心状态变量
// 三个状态变量构成一把读写锁
private exclusiveLock = false; // 当前是否有独占锁持有者
private concurrentCount = 0; // 当前共享锁持有数
private waitQueue: Array<() => void> = []; // 阻塞等待中的 resolve 函数
我们用图书馆来做完美类比:
| 变量名 | 类型 | 对应图书馆的什么 | 作用 |
|---|---|---|---|
exclusiveLock | 布尔值 | 门口挂的 "正在整理中,禁止入内" 牌子 | 只要是true,任何人都不能进图书馆 |
concurrentCount | 数字 | 现在图书馆里有多少个读者 | 只要大于 0,就不能进人整理书架,但可以继续进读者 |
waitQueue | 函数数组 | 门口排队的人的 "叫醒电话" | 存的是所有拿不到锁、正在睡觉等待的人的resolve函数,等图书馆空了就挨个打电话叫醒 |
💡 关键认知:JavaScript 是单线程的!所以这三个变量的修改永远是原子操作,不会出现两个地方同时改同一个变量的情况。这是这个锁能工作的根本前提。
锁的四个核心方法
-
拿共享锁(读者进图书馆):
acquireConcurrent()private async acquireConcurrent(): Promise<void> { // 只要有人在整理书架(有独占锁),我就不能进 while (this.exclusiveLock) { // 把我的叫醒电话留在门口,然后睡觉 await new Promise<void>(resolve => this.waitQueue.push(resolve)); } // 没人整理,我进去了,读者数量+1 this.concurrentCount++; }你走到图书馆门口,先看有没有挂 "正在整理" 的牌子
如果挂了,你就把手机号留给保安,然后去旁边椅子上睡觉
保安叫醒你之后,你必须再看一眼牌子(这就是为什么用
while而不是if!)- 因为可能你睡着的时候,又有别人先进去整理了
- 如果还用
if,你醒了直接进去,就会和整理书架的人撞个正着
确认没牌子了,你就进去,保安在本子上记 "当前读者数 + 1"
-
释放共享锁(读者离开图书馆):
releaseConcurrent()你看完书离开,保安把读者数减 1
如果你是最后一个离开的,图书馆空了,保安就会拿出刚才留的手机号名单,挨个打电话叫醒所有排队的人
private releaseConcurrent(): void { // 我走了,读者数量-1 this.concurrentCount--; // 如果我是最后一个走的,就告诉保安可以叫排队的人了 if (this.concurrentCount === 0) this.drainQueue(); } -
拿独占锁(整理员进图书馆):
acquireExclusive()你是整理员,走到门口先看两个条件:
- 有没有别人已经在整理了?
- 里面有没有读者在看书?
只要满足其中一个,你就不能进,留手机号睡觉
被叫醒后再检查一遍,直到两个条件都不满足
进去之后,立刻挂上 "正在整理中,禁止入内" 的牌子
private async acquireExclusive(): Promise<void> { // 两个条件:要么有人在整理,要么里面有读者,我都不能进 while (this.exclusiveLock || this.concurrentCount > 0) { // 把我的叫醒电话留在门口,然后睡觉 await new Promise<void>(resolve => this.waitQueue.push(resolve)); } // 没人也没整理的,我进去了,挂上"正在整理"的牌子 this.exclusiveLock = true; } -
释放独占锁(整理员离开图书馆):
releaseExclusive()private releaseExclusive(): void { // 我整理完了,摘掉牌子 this.exclusiveLock = false; // 告诉保安可以叫排队的人了 this.drainQueue(); }你整理完书架,摘掉门口的牌子
然后告诉保安,现在可以叫醒所有排队的人了
-
最容易误解的方法:
drainQueue()private drainQueue(): void { // 把所有排队的人的手机号全部拿出来 const waiting = this.waitQueue.splice(0); // 挨个打电话叫醒所有人 for (const resolve of waiting) resolve(); }它不是 "按顺序分配锁",而是把所有等待的人全部叫醒,让他们自己去抢锁。JavaScript 是单线程的,所有
resolve都会按顺序进入微任务队列,不会真的 "同时抢"
代码细节 【vibe coding太久了,基本功都遗忘了】
await new Promise<void>(resolve => this.waitQueue.push(resolve));
-
Promise 内部的函数是 同步立即执行 (和异步、宏任务、微任务完全无关。)
r => this.waitQueue.push(r) -
await 会阻塞,直到 Promise 被 resolve ,因为我们没有调用 resolve (),所以 Promise 永远处于 **pending(等待中)**于是:
await 就卡在这一行,代码不动了,暂停了。
-
当别人从数组里拿出 r,并执行:
resolve()这时:
- Promise 被 resolve
- await 结束等待
- 暂停的代码继续往下走
- 阻塞解除
完整register代码
import { jsonSchema } from "ai";
/**
* 工具定义接口(AI 调用工具的标准结构)
* 所有文件读写、目录操作等工具都必须遵循这个接口
*/
export interface ToolDefinition {
name: string; // 工具唯一名称(如 read_file)
description: string; // 工具描述,用于 AI 理解功能
parameters: Record<string, unknown>; // 参数定义(JSON Schema 格式)
isConcurrencySafe?: boolean; // 是否并发安全:读安全,写不安全
isReadOnly?: boolean; // 是否只读:读文件/目录是只读,写不是
maxResultChars?: number; // 结果最大字符数,防止返回内容过长
execute: (input: any) => Promise<unknown>; // 工具执行函数(异步)
}
/**
* 默认最大返回字符数(未配置时使用)
*/
const DEFAULT_MAX_RESULT_CHARS = 3000;
/**
* 工具注册器
* 作用:统一管理、存储、查询所有 AI 工具
* 提供注册、获取、转 AI SDK 格式等能力
*/
export class ToolRegistry {
// 三个状态变量构成一把读写锁
private exclusiveLock = false; // 当前是否有独占锁持有者
private concurrentCount = 0; // 当前共享锁持有数
private waitQueue: Array<() => void> = []; // 阻塞等待中的 resolve 函数
// 获取共享锁:只要没人独占就能拿,多个只读工具可以同时持有
private async acquireConcurrent(): Promise<void> {
while (this.exclusiveLock) {
await new Promise<void>((resolve) => this.waitQueue.push(resolve));
}
this.concurrentCount++;
}
private releaseConcurrent(): void {
this.concurrentCount--;
if (this.concurrentCount === 0) this.drainQueue();
}
// 获取独占锁:必须等所有共享锁释放、且没人持独占
private async acquireExclusive(): Promise<void> {
while (this.exclusiveLock || this.concurrentCount > 0) {
await new Promise<void>((resolve) => this.waitQueue.push(resolve));
}
this.exclusiveLock = true;
}
private releaseExclusive(): void {
this.exclusiveLock = false;
this.drainQueue();
}
// 锁释放时把等待队列全唤醒,让它们重新去抢锁
private drainQueue(): void {
const waiting = this.waitQueue.splice(0);
for (const resolve of waiting) resolve();
}
// 内部用 Map 存储所有工具:key=工具名,value=工具定义
private tools = new Map<string, ToolDefinition>();
/**
* 注册一个或多个工具
* @param tools 工具列表
*/
register(...tools: ToolDefinition[]): void {
for (const tool of tools) {
this.tools.set(tool.name, tool);
}
}
/**
* 根据工具名称获取工具
* @param name 工具名
* @returns 工具定义 或 undefined
*/
get(name: string): ToolDefinition | undefined {
return this.tools.get(name);
}
/**
* 获取所有已注册的工具
* @returns ToolDefinition[]
*/
getAll(): ToolDefinition[] {
return Array.from(this.tools.values());
}
/**
* 转换为 Vercel AI SDK 支持的工具格式
* 这是核心方法:把自定义工具 → AI 可调用的标准格式
* 自动包装执行逻辑 + 自动截断超长返回内容
*/
toAISDKFormat(): Record<string, any> {
const result: Record<string, any> = {};
for (const [name, tool] of this.tools) {
const maxChars = tool.maxResultChars;
const executeFn = tool.execute;
const isSafe = tool.isConcurrencySafe;
const registry = this;
// 构建 AI SDK 标准工具结构
result[name] = {
description: tool.description,
inputSchema: jsonSchema(tool.parameters as any), // 转为 AI SDK 需要的 schema
execute: async (input: any) => {
try {
if (isSafe) {
await registry.acquireConcurrent();
console.log(` [并发] ${name} 获取共享锁`);
} else {
await registry.acquireExclusive();
console.log(` [串行] ${name} 获取独占锁,等待其他工具完成`);
}
// 1. 执行原工具逻辑
const raw = await executeFn(input);
// 2. 统一转为字符串(非字符串则格式化 JSON)
const text =
typeof raw === "string" ? raw : JSON.stringify(raw, null, 2);
// 3. 截断超长内容,避免 token 爆炸
return truncateResult(text, maxChars);
} finally {
if (isSafe) {
registry.releaseConcurrent();
} else {
registry.releaseExclusive();
}
}
},
};
}
return result;
}
}
/**
* 截断超长文本(中间省略,保留前后关键内容)
* 避免 AI 收到过长内容导致 token 超限、响应变慢
*
* 策略:前 60% + 省略提示 + 后 40%
*
* @param text 原始文本
* @param maxChars 最大允许长度
* @returns 截断后的文本
*/
export function truncateResult(
text: string,
maxChars: number = DEFAULT_MAX_RESULT_CHARS,
): string {
// 长度没超限,直接返回
if (text.length <= maxChars) return text;
// 计算前后保留长度
const headSize = Math.floor(maxChars * 0.6);
const tailSize = maxChars - headSize;
// 截取前后内容
const head = text.slice(0, headSize);
const tail = text.slice(-tailSize);
// 计算省略了多少字符
const dropped = text.length - headSize - tailSize;
// 拼接最终结果
return `${head}\n\n... [省略 ${dropped} 字符] ...\n\n${tail}`;
}
4. Mock Model模拟并发
如果要模拟大模型并发调用多个tools的格式!
一次工具调用的的 tools chunk
{ type: "tool-input-start", id: callId, toolName: intent.toolName },
{ type: "tool-input-delta", id: callId, delta: argsJson },
{ type: "tool-input-end", id: callId },
{ type: "tool-call", toolCallId: callId, toolName: intent.toolName, input: argsJson },
含义大致是:
| chunk | 作用 |
|---|---|
tool-input-start | 开始「生成这次调用的参数」,id 标识这一次调用 |
tool-input-delta | 参数 JSON 的一段(真实模型会分多段 delta;Mock 一次给全) |
tool-input-end | 参数流结束 |
tool-call | 定稿:这次要调哪个工具、参数是什么;SDK 靠它去 execute |
先流式吐出参数 → 最后落成一条可执行的 tool-call。
多个工具 = 多组 4 个 chunk 连在一起 + 一个 finish
并发 2 个工具时,chunk 顺序类似:
[工具1] start → delta → end → tool-call
[工具2] start → delta → end → tool-call
[整步结束] finish (finishReason: "tool-calls")
ok 了解了 tool- call的chunk结构,我们可以先模拟返回多个tool调用 返回好一组 toolName 及调用参数的对象!
这里我之前学晕了搞混掉,所以在这里单独记录一下, 同一轮 Loop 跑完后,SDK 会整理成 聊天记录,形态和 chunk 列表不一样:
比如我们通过流把上面的chunk通过流式返回了SDK会组装成messages
start → delta → end → tool-call // 工具 1 start → delta → end → tool-call // 工具 2 … finish (finishReason: "tool-calls")SDK处理这些格式的Stream 转换为
[ { role: "assistant", content: [ 多个 { type: "tool-call", toolCallId, toolName, input } ] }, { role: "tool", content: [ 多个 { type: "tool-result", toolCallId, toolName, output } ] } ]执行小细节
- 工具是在 Loop 中间执行的
不是等 chunk 全吐完才执行:SDK 每解析出一个tool-call,就会调execute,然后流里再来tool-result。
messages.push一般在这次streamText的finish时,用await result.response一次性拿齐本 Step 的 assistant + tool。- 下次
streamText时,SDK 把这整段当作prompt传给doStream,所以 最后一条是role: "tool",表示:上一轮工具已经调完,结果也进上下文了。
/**
* 命中「测试并发」时返回多个 ToolIntent,由 buildParallelIntentChunks 打成流式 chunk。
* 因为tool-call tool-result都会在一次loop 调用和结果返回,所以下一次要先判断有没有tool-result!
* 如果没有判断,那 role 为 user 的prompt content还是测试并发,就循环了!触发 detect 的乒乓警告
*/
function detectParallelIntent(prompt: PromptMessage[]): ToolIntent[] | null {
if (isRespondingToToolResult(prompt)) return null; // Step2+:prompt 末尾已是 tool,勿再发 tool-call
const text = getLastUserText(prompt);
if (text.includes("测试并发") || text.includes("test parallel")) {
return [
{
toolName: "read_file",
args: { path: "/Users/cunwangbro/agent-sdy/1.txt" },
},
{
toolName: "read_file",
args: { path: "/Users/cunwangbro/agent-sdy/1.txt" },
},
{
toolName: "read_file",
args: { path: "/Users/cunwangbro/agent-sdy/1.txt" },
},
{
toolName: "write_file",
args: {
path: "/Users/cunwangbro/agent-sdy/1.txt",
content: new Date().toLocaleTimeString(),
},
},
{
toolName: "read_file",
args: { path: "/Users/cunwangbro/agent-sdy/1.txt" },
},
];
}
return null;
}
然后再交给 buildParallelIntentChunks 拼成最终的流式层 chunk
buildParallelIntentChunks 里就是 for 循环推 parallelIntents 组,最后只 push 一次 finish。
function buildParallelIntentChunks(parallelIntents: ToolIntent[]) {
const chunks: unknown[] = [];
for (const intent of parallelIntents) {
const callId = `call-${Date.now()}-${Math.random().toString(36).slice(2, 6)}`;
const argsJson = JSON.stringify(intent.args);
// 下面 4 个 chunk 描述「一次工具调用」;并发时重复 N 次,共用同一个 finish
chunks.push(
{ type: "tool-input-start", id: callId, toolName: intent.toolName },
{ type: "tool-input-delta", id: callId, delta: argsJson },
{ type: "tool-input-end", id: callId },
{
type: "tool-call",
toolCallId: callId,
toolName: intent.toolName,
input: argsJson, // 流式层是 JSON 字符串;汇总进 messages 时 SDK 会 parse 成 object
},
);
}
chunks.push({
type: "finish",
finishReason: { unified: "tool-calls", raw: undefined },
usage: makeUsage(),
});
return chunks;
}
然后我们在检测 prompt 的最后一条用户消息的意图!多加一个 detectParallelIntent,检测到了就给 buildParallelIntentChunks 拼装并发的tool- call chunks 流式返回!
/** index.ts 每跑一轮 Loop 就会调一次这里,相当于假模型回一句话或调一批工具 */
async doStream({ prompt }: { prompt: PromptMessage[] }) {
// prompt 里已经是到此刻为止的聊天记录;最后一条是 user 说明刚接到新问题,是 tool 说明上轮工具刚跑完
// 用户说了「测试并发」?只在第一轮返回「要写/要读」好几个工具,第二轮必须停
const parallelIntent = detectParallelIntent(prompt);
// 普通单工具:查天气、算数、死循环测试等;第二轮同样不会再调工具
const intent = detectToolIntent(prompt);
let chunks: unknown[];
if (intent) {
// 只调一个工具,跑完 index 会再进 Loop 把结果喂回来
chunks = buildToolCallChunks(intent);
} else if (parallelIntent !== null) {
// 同一轮里连着调好几个工具,跑完同样会再进 Loop
chunks = buildParallelIntentChunks(parallelIntent);
} else {
// 不调工具了:要么把上轮工具结果念给用户,要么回固定话术
chunks = buildTextChunks(resolveTextResponse(prompt));
}
// 包一层慢速流,控制台好跟着看;SDK 要的就是 { stream }
return { stream: createDelayedStream(chunks) };
},
这样我们的测试并发的Mock Model就写好了!
但是其实现在的并发锁的效果不是很明显,因为执行过快,看不出来!
我们现在写了三个 read_file 在前面,然后一个 write_file 在后面!然后最后又加了一个read_file
为了能很好的看出来效果,我在read_file和write_file工具都增加了一点模拟耗时操作!这样如果抢了锁,需要一点时间能看得出有等待锁的日志!
export const readFileTool: ToolDefinition = {
name: "read_file",
description: "读取指定路径的文件内容",
parameters: {
type: "object",
properties: {
path: { type: "string", description: "文件路径" },
},
required: ["path"],
additionalProperties: false,
},
isConcurrencySafe: true,
isReadOnly: true,
maxResultChars: 500,
execute: async ({ path }: { path: string }) => {
const resolved = resolve(path);
const callId = `reading-${new Date().getTime()}`;
console.log(`${callId}-正在读取文件`);
await new Promise((resolve) =>
setTimeout(() => {
resolve(null);
}, 10000 * Math.random()),
);
console.log(`${callId}-读取文件完成`);
return readFileSync(resolved, "utf-8");
},
};
export const writeFileTool: ToolDefinition = {
name: "write_file",
description: "写入内容到指定文件。如果文件已存在则覆盖",
parameters: {
type: "object",
properties: {
path: { type: "string", description: "文件路径" },
content: { type: "string", description: "要写入的内容" },
},
required: ["path", "content"],
additionalProperties: false,
},
isConcurrencySafe: false,
isReadOnly: false,
execute: async ({ path, content }: { path: string; content: string }) => {
const callId = `reading-${new Date().getTime()}`;
console.log(`${callId}-正在写入文件`);
await new Promise((resolve) =>
setTimeout(() => {
resolve(null);
}, 10000 * Math.random()*2),
);
console.log(`${callId}-写入文件完成`);
const resolved = resolve(path);
writeFileSync(resolved, content, "utf-8");
return `已写入 ${content.length} 字符到 ${path}`;
},
};
然后对 concurrentCount 做了get / set 监听值变化
import { jsonSchema } from "ai";
/**
* 工具定义接口(AI 调用工具的标准结构)
* 所有文件读写、目录操作等工具都必须遵循这个接口
*/
export interface ToolDefinition {
name: string; // 工具唯一名称(如 read_file)
description: string; // 工具描述,用于 AI 理解功能
parameters: Record<string, unknown>; // 参数定义(JSON Schema 格式)
isConcurrencySafe?: boolean; // 是否并发安全:读安全,写不安全
isReadOnly?: boolean; // 是否只读:读文件/目录是只读,写不是
maxResultChars?: number; // 结果最大字符数,防止返回内容过长
execute: (input: any) => Promise<unknown>; // 工具执行函数(异步)
}
/**
* 默认最大返回字符数(未配置时使用)
*/
const DEFAULT_MAX_RESULT_CHARS = 3000;
/**
* 工具注册器
* 作用:统一管理、存储、查询所有 AI 工具
* 提供注册、获取、转 AI SDK 格式等能力
*/
export class ToolRegistry {
// 三个状态变量构成一把读写锁
private exclusiveLock = false; // 当前是否有独占锁持有者
private _concurrentCount = 0; // 当前共享锁持有数
private waitQueue: Array<() => void> = []; // 阻塞等待中的 resolve 函数
// 获取共享锁:只要没人独占就能拿,多个只读工具可以同时持有
private async acquireConcurrent(): Promise<void> {
while (this.exclusiveLock) {
await new Promise<void>((resolve) => this.waitQueue.push(resolve));
}
this.concurrentCount++;
}
get concurrentCount(): number {
return this._concurrentCount;
}
private set concurrentCount(value: number) {
if (this._concurrentCount !== value) {
this._concurrentCount = value;
// 只有值真正改变时才触发回调
this.onConcurrentCountChange(value);
}
}
onConcurrentCountChange(val: number) {
console.log("图书馆有" + val + "个人");
}
private releaseConcurrent(): void {
this.concurrentCount--;
if (this.concurrentCount === 0) this.drainQueue();
}
// 获取独占锁:必须等所有共享锁释放、且没人持独占
private async acquireExclusive(): Promise<void> {
console.log("需要独占锁的write_file 尝试执行");
while (this.exclusiveLock || this.concurrentCount > 0) {
await new Promise<void>((resolve) => this.waitQueue.push(resolve));
}
console.log("需要独占锁的write_file 可以执行了");
this.exclusiveLock = true;
}
private releaseExclusive(): void {
this.exclusiveLock = false;
this.drainQueue();
}
// 锁释放时把等待队列全唤醒,让它们重新去抢锁
private drainQueue(): void {
const waiting = this.waitQueue.splice(0);
for (const resolve of waiting) resolve();
}
// 内部用 Map 存储所有工具:key=工具名,value=工具定义
private tools = new Map<string, ToolDefinition>();
/**
* 注册一个或多个工具
* @param tools 工具列表
*/
register(...tools: ToolDefinition[]): void {
for (const tool of tools) {
this.tools.set(tool.name, tool);
}
}
/**
* 根据工具名称获取工具
* @param name 工具名
* @returns 工具定义 或 undefined
*/
get(name: string): ToolDefinition | undefined {
return this.tools.get(name);
}
/**
* 获取所有已注册的工具
* @returns ToolDefinition[]
*/
getAll(): ToolDefinition[] {
return Array.from(this.tools.values());
}
/**
* 转换为 Vercel AI SDK 支持的工具格式
* 这是核心方法:把自定义工具 → AI 可调用的标准格式
* 自动包装执行逻辑 + 自动截断超长返回内容
*/
toAISDKFormat(): Record<string, any> {
const result: Record<string, any> = {};
for (const [name, tool] of this.tools) {
const maxChars = tool.maxResultChars;
const executeFn = tool.execute;
const isSafe = tool.isConcurrencySafe;
const registry = this;
// 构建 AI SDK 标准工具结构
result[name] = {
description: tool.description,
inputSchema: jsonSchema(tool.parameters as any), // 转为 AI SDK 需要的 schema
execute: async (input: any) => {
try {
if (isSafe) {
await registry.acquireConcurrent();
console.log(` [并发] ${name} 获取共享锁`);
} else {
await registry.acquireExclusive();
console.log(` [串行] ${name} 获取独占锁,等待其他工具完成`);
}
// 1. 执行原工具逻辑
const raw = await executeFn(input);
// 2. 统一转为字符串(非字符串则格式化 JSON)
const text =
typeof raw === "string" ? raw : JSON.stringify(raw, null, 2);
// 3. 截断超长内容,避免 token 爆炸
return truncateResult(text, maxChars);
} finally {
if (isSafe) {
registry.releaseConcurrent();
} else {
registry.releaseExclusive();
}
}
},
};
}
return result;
}
}
/**
* 截断超长文本(中间省略,保留前后关键内容)
* 避免 AI 收到过长内容导致 token 超限、响应变慢
*
* 策略:前 60% + 省略提示 + 后 40%
*
* @param text 原始文本
* @param maxChars 最大允许长度
* @returns 截断后的文本
*/
export function truncateResult(
text: string,
maxChars: number = DEFAULT_MAX_RESULT_CHARS,
): string {
// 长度没超限,直接返回
if (text.length <= maxChars) return text;
// 计算前后保留长度
const headSize = Math.floor(maxChars * 0.6);
const tailSize = maxChars - headSize;
// 截取前后内容
const head = text.slice(0, headSize);
const tail = text.slice(-tailSize);
// 计算省略了多少字符
const dropped = text.length - headSize - tailSize;
// 拼接最终结果
return `${head}\n\n... [省略 ${dropped} 字符] ...\n\n${tail}`;
}
完整的执行日志!
╭─░▒▓ ~/agent-sdy on main !3 ?4 ▓▒░························································································░▒▓ ✔ at 07:14:06 PM ▓▒░
╰─ npm run start
> agent-sdy@1.0.0 start
> tsx src/index.ts
You: 测试并发
AI SDK Warning System: To turn off warning logging, set the AI_SDK_LOG_WARNINGS global to false.
AI SDK Warning (mock / tiny-model): The feature "specificationVersion" is used in a compatibility mode. Using v2 specification compatibility mode. Some features may not be available.
【==================================开始Loop_1_==================================】
图书馆有1个人
正在调用工具read_file call-1779880488653-t9p7
【==================================看来还需要多一轮,来处理本轮"read_file"的调用结果==================================】
[并发] read_file 获取共享锁
reading-1779880488959-正在读取文件
图书馆有2个人
正在调用工具read_file call-1779880488653-l4fq
【==================================看来还需要多一轮,来处理本轮"read_file"的调用结果==================================】
[并发] read_file 获取共享锁
reading-1779880489361-正在读取文件
图书馆有3个人
正在调用工具read_file call-1779880488653-joxw
【==================================看来还需要多一轮,来处理本轮"read_file"的调用结果==================================】
[并发] read_file 获取共享锁
reading-1779880489766-正在读取文件
需要独占锁的write_file 尝试执行
正在调用工具write_file call-1779880488653-i8tw
【==================================看来还需要多一轮,来处理本轮"write_file"的调用结果==================================】
图书馆有4个人
正在调用工具read_file call-1779880488653-0cn1
【==================================看来还需要多一轮,来处理本轮"read_file"的调用结果==================================】
[并发] read_file 获取共享锁
reading-1779880490576-正在读取文件
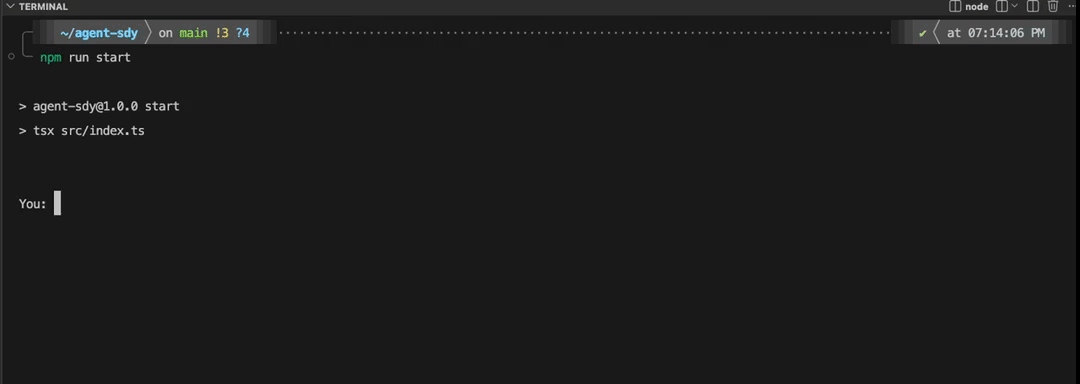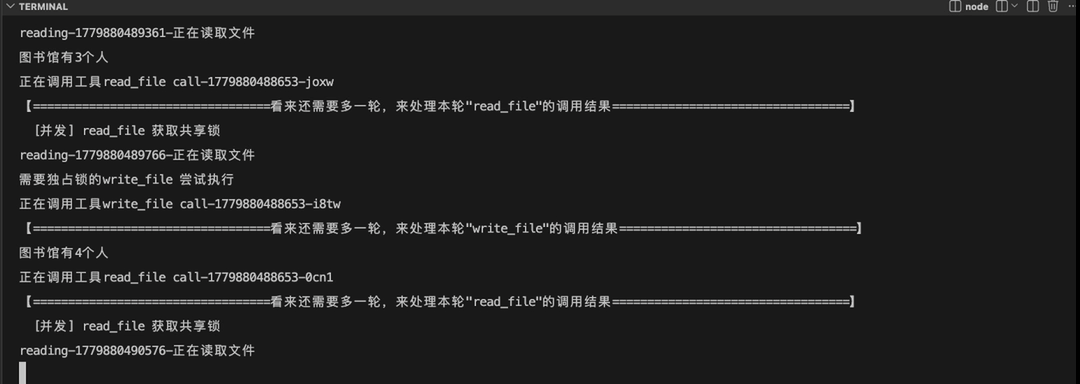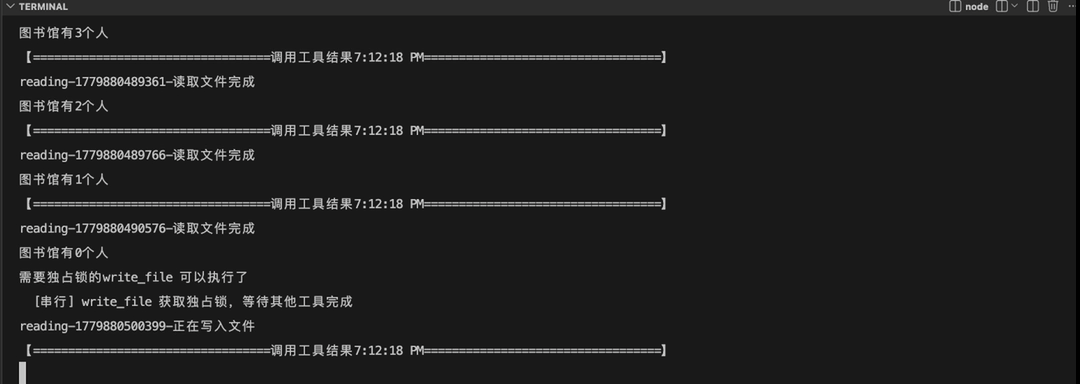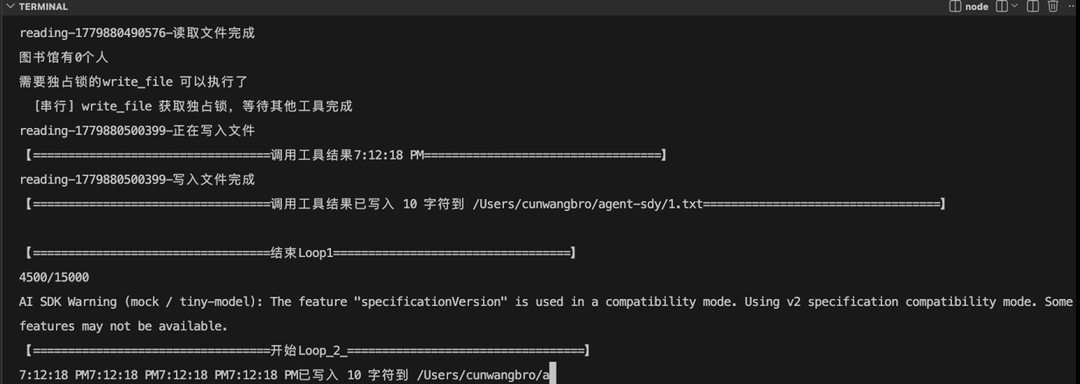
reading-1779880488959-读取文件完成
图书馆有3个人
【==================================调用工具结果7:12:18 PM==================================】
reading-1779880489361-读取文件完成
图书馆有2个人
【==================================调用工具结果7:12:18 PM==================================】
reading-1779880489766-读取文件完成
图书馆有1个人
【==================================调用工具结果7:12:18 PM==================================】
reading-1779880490576-读取文件完成
图书馆有0个人
需要独占锁的write_file 可以执行了
[串行] write_file 获取独占锁,等待其他工具完成
reading-1779880500399-正在写入文件
【==================================调用工具结果7:12:18 PM==================================】
reading-1779880500399-写入文件完成
【==================================调用工具结果已写入 10 字符到 /Users/cunwangbro/agent-sdy/1.txt==================================】
【==================================结束Loop1==================================】
4500/15000
AI SDK Warning (mock / tiny-model): The feature "specificationVersion" is used in a compatibility mode. Using v2 specification compatibility mode. Some features may not be available.
【==================================开始Loop_2_==================================】
7:12:18 PM7:12:18 PM7:12:18 PM7:12:18 PM已写入 10 字符到 /Users/cunwangbro/agent-sdy/1.txt
【==================================结束Loop2==================================】
9000/15000
You:
可以看到是符合预期的!
一开始三个共享锁在里面,需要独占锁的write_file 尝试执行,但是因为有三个共享锁,没有执行!
直到
图书馆有0个人
需要独占锁的 write_file 可以执行了
顺便提一句:虽然协议层靠
toolCallId匹配结果和调用,乱序返回技术上没问题,但实践中建议按调用顺序组织结果。原因不是模型会搞混,而是日志排查和行为确定性——异步完成顺序每次可能不同,按调用顺序返回让整个执行过程可预测、可复现。
到这里,你的 Agent 有了一个像样的工具系统。回头看看我们做的事情:
ToolRegistry 解耦了工具定义和使用——注册一次,Agent Loop 和 AI SDK 都能用。加新工具只需要写一个 ToolDefinition 对象,调一下 registry.register(),不用改 Agent Loop 的任何代码。
结果截断 是上下文工程的第一道防线——不让单个工具的输出吃掉整个推理空间。Head/Tail 60/40 分割比简单截头更聪明,保留了文件两端的关键信息。
读写锁并发控制 让只读工具并行跑、读写工具独占执行,Agent Loop 完全不需要感知并发细节。
而且上一篇的三层防护(循环检测、API 容错、Token 预算)完全没动——它们在更外层保护 Agent Loop,和工具系统互不干扰。这就是分层设计的好处。
5. 补齐其他工具装备——edit_file、grep、glob 与 bash
Agent 手里的工具还是太少了——能读文件、能列目录,但不能编辑文件、不能搜索内容、不能跑命令。你让它"帮我把 package.json 里的版本号改成 2.0",它只能 write_file 把整个文件重写一遍。
1. edit_file:精确替换,不是全量覆写
write_file 的问题是它会覆盖整个文件。模型要改一行代码,得把整个文件内容重新生成一遍——不仅浪费 token,还容易出错(模型可能"不小心"改了其他地方)。
edit_file 的思路完全不同:你告诉我要替换哪段文本(old_string),替换成什么(new_string),我只改你指定的部分。值得一提的是,这就是 Claude Code 的 Edit 工具采用的方式。
export const editFileTool: ToolDefinition = {
name: 'edit_file',
description: '精确替换文件中的指定内容。用 old_string 定位要替换的文本,用 new_string 替换它。不是全量覆写——只改你指定的部分',
parameters: {
type: 'object',
properties: {
path: { type: 'string', description: '文件路径' },
old_string: { type: 'string', description: '要被替换的原始文本(必须精确匹配)' },
new_string: { type: 'string', description: '替换后的新文本' },
},
required: ['path', 'old_string', 'new_string'],
additionalProperties: false,
},
isConcurrencySafe: false,
isReadOnly: false,
execute: async ({ path, old_string, new_string }) => {
const resolved = resolve(path);
if (!existsSync(resolved)) return `文件不存在: ${path}`;
const content = readFileSync(resolved, 'utf-8');
const count = content.split(old_string).length - 1;
if (count === 0) {
return `未找到匹配内容。请检查 old_string 是否与文件中的文本完全一致(包括空格和换行)`;
}
if (count > 1) {
return `找到 ${count} 处匹配,请提供更多上下文让 old_string 唯一`;
}
const updated = content.replace(old_string, new_string);
writeFileSync(resolved, updated, 'utf-8');
return `已替换 ${path} 中的内容(${old_string.length} → ${new_string.length} 字符)`;
},
};
这里有两个关键的错误处理:
匹配数为 0:模型给的 old_string 在文件里根本不存在。最常见的原因是模型记错了缩进或者多了少了一个空格。返回明确的错误信息,让模型知道"你的匹配不对,再看看"。
匹配数大于 1:old_string 在文件里出现了多次。这时候直接替换会改错地方。让模型提供更多上下文(比如多包含前后几行),确保唯一匹配。
这两种错误信息的设计很重要——它们不是给人看的,是给模型看的。模型收到错误后会根据信息调整策略:匹配不到就换个写法,多个匹配就扩大范围。好的错误信息能让模型自我修正,差的错误信息只会让模型更困惑。
执行测试一下!
╭─░▒▓ ~/agent-sdy on main !2 ▓▒░······················································································░▒▓ ✔ at 01:53:21 PM ▓▒░
╰─ npm run start
> agent-sdy@1.0.0 start
> tsx src/index.ts
You: '/Users/cunwangbro/agent-sdy/1.txt'把里面的朝代都换成完整的朝代名称+年份
【==================================开始Loop_1_==================================】
图书馆有1个人
正在调用工具read_file call_bb2536ee03c64865ab89f0
【==================================看来还需要多一轮,来处理本轮"read_file"的调用结果==================================】
[并发] read_file 获取共享锁
reading-1779948087617-正在读取文件
> reading-1779948087617-读取文件完成
图书馆有0个人
【==================================调用工具结果《静夜思》
唐·李白
床前明月光,疑是地上霜。
举头望明月,低头思故乡。
━━━━━━━━━━━━━━━━━━━━
【诗意解释】
首句“床前明月光”,以白描手法勾勒出静谧秋夜:清冷月光洒落卧榻之前,澄澈如水。“疑是地上霜”,“疑”字传神写出诗人半梦半醒间的错觉——月华皎洁凛冽,竟恍若寒霜覆地,既强化了环境的清寂清寒,又悄然埋下孤寂情绪的伏笔。
后两句直抒胸臆:“举头望明月”是动作的延展,更是心绪的升腾;“低头思故乡”则以极简姿态完成情感的沉淀与聚焦。一“举”一“低”,俯仰之间,空间收放自如,将无形乡愁具象为可触可感的生命律动。
━━━━━━
【理解与赏析题】
1. “疑是地上霜”中的“疑
... [省略 7 字符] ...
果?请结合诗句简要分析。(2分)
2. 本诗后两句“举头望明月,低头思故乡”未用任何形容词,却极具感染力。请从动作描写角度赏析其妙处。(3分)
3. 全诗无一“愁”字,却字字含情。请结合意象与情感关系,分析诗人如何表达深切的思乡之情。(3分)
4. 【文化拓展】“明月”在中国古典诗歌中常为思乡怀远的象征(如杜甫“露从今夜白,月是故乡明”)。请再举一例含“明月”的古诗句,并简述其寄托的情感。(2分)==================================】
【==================================结束Loop1==================================】
709/15000
【==================================开始Loop_2_==================================】
需要独占锁的write_file 尝试执行
需要独占锁的write_file 可以执行了
正在调用工具edit_file call_c461ab4fda344f40aa6651
【==================================看来还需要多一轮,来处理本轮"edit_file"的调用结果==================================】
[串行] edit_file 获取独占锁,等待其他工具完成
【==================================调用工具结果已替换 /Users/cunwangbro/agent-sdy/1.txt 中的内容(4 → 16 字符)==================================】
【==================================结束Loop2==================================】
1892/15000
【==================================开始Loop_3_==================================】
文件 `/Users/cunwangbro/agent-sdy/1.txt` 中的“唐·李白”已成功替换为“唐朝(618年-907年)·李白”。如需进一步处理其他朝代或内容,请随时告诉我!
【==================================结束Loop3==================================】
3169/15000
You:
替换后
《静夜思》
唐朝(618年-907年)·李白
床前明月光,疑是地上霜。
举头望明月,低头思故乡。
━━━━━━━━━━━━━━━━━━━━
【诗意解释】
首句“床前明月光”,以白描手法勾勒出静谧秋夜:清冷月光洒落卧榻之前,澄澈如水。“疑是地上霜”,“疑”字传神写出诗人半梦半醒间的错觉——月华皎洁凛冽,竟恍若寒霜覆地,既强化了环境的清寂清寒,又悄然埋下孤寂情绪的伏笔。
后两句直抒胸臆:“举头望明月”是动作的延展,更是心绪的升腾;“低头思故乡”则以极简姿态完成情感的沉淀与聚焦。一“举”一“低”,俯仰之间,空间收放自如,将无形乡愁具象为可触可感的生命律动。
━━━━━━
【理解与赏析题】
1. “疑是地上霜”中的“疑”字有何表达效果?请结合诗句简要分析。(2分)
2. 本诗后两句“举头望明月,低头思故乡”未用任何形容词,却极具感染力。请从动作描写角度赏析其妙处。(3分)
3. 全诗无一“愁”字,却字字含情。请结合意象与情感关系,分析诗人如何表达深切的思乡之情。(3分)
4. 【文化拓展】“明月”在中国古典诗歌中常为思乡怀远的象征(如杜甫“露从今夜白,月是故乡明”)。请再举一例含“明月”的古诗句,并简述其寄托的情感。(2分)
2. glob:按模式找文件
Agent 要修改代码,第一步往往是"先看看项目里有哪些文件"。list_directory 只能看一层目录,glob 可以递归搜索。
fast-glob 该包提供了遍历文件系统的方法,并会根据 Unix Bash shell 的规则(已做部分简化)返回与指定模式的定义集合匹配的路径名,同时结果以任意顺序返回。便捷、简单、高效。
Some examples: 一些示例:
src/**/*.js— matches all files in thesrcdirectory (any level of nesting) that have the.jsextension.src/**/*.js— 匹配src目录中所有扩展名为.js的文件(包括任意层级的子目录)。src/*.??— matches all files in thesrcdirectory (only first level of nesting) that have a two-character extension.src/*.??— 匹配src目录中所有具有两个字符扩展名的文件(仅一级子目录)。file-[01].js— matches files:file-0.js,file-1.js.file-[01].js— 匹配文件:file-0.js、file-1.js。
import fg from 'fast-glob';
export const globTool: ToolDefinition = {
name: 'glob',
description: '按模式搜索文件。支持 * 和 ** 通配符,如 "src/**/*.ts" 匹配 src 下所有 TypeScript 文件',
parameters: {
type: 'object',
properties: {
pattern: { type: 'string', description: '搜索模式,如 "**/*.ts"、"src/*.json"' },
path: { type: 'string', description: '搜索起始目录,默认当前目录' },
},
required: ['pattern'],
additionalProperties: false,
},
isConcurrencySafe: true,
isReadOnly: true,
execute: async ({ pattern, path = '.' }: { pattern: string; path?: string }) => {
const results = await fg(pattern, {
cwd: resolve(path),
ignore: ['node_modules/**', '.git/**'],
dot: false,
onlyFiles: true,
followSymbolicLinks: false,
});
if (results.length === 0) return `没有找到匹配 "${pattern}" 的文件`;
return results.sort().join('\n');
},
};
跑下测试:
─░▒▓ ~/agent-sdy on main !1691 ?45 ▓▒░···············································································░▒▓ ✔ at 03:03:52 PM ▓▒░
╰─ npm run start
> agent-sdy@1.0.0 start
> tsx src/index.ts
You: 帮我查看src有哪些ts文件
【==================================开始Loop_1_==================================】
图书馆有1个人
正在调用工具glob call_449196b780c14b0d979849
【==================================看来还需要多一轮,来处理本轮"glob"的调用结果==================================】
[并发] glob 获取共享锁
图书馆有0个人
【==================================调用工具结果src/1.基础输出.ts
src/2.一个带有记忆历史的可以反复对话的Agent.ts
src/3.尝试使用system.ts
src/4.使用Model Message的 system类型.ts
src/5.封装call Model返回值为完全的响应文本.ts
src/6.手动agent loop实现.ts
src/7.测试死循环调用.ts
src/achive/1.基础输出.ts
src/achive/2.一个带有记忆历史的可以反复对话的Agent.ts
src/achive/3.尝试使用system.ts
src/achive/4.使用Model Message的 system类型.ts
src/achive/5.封装call Model返回值为完全的响应文本.ts
src/budge/index.ts
src/detect/helper.ts
src/detect/index.ts
src/detect/types.ts
src/index.ts
src/mock-model/index.ts
src/retry/constants.ts
src/retry/help.ts
src/tools/get_weather.ts
src/tools/tool-register.ts
src/tools/utility-tools.ts==================================】
【==================================结束Loop1==================================】
801/15000
【==================================开始Loop_2_==================================】
在 `src` 目录及其子目录中,共找到以下 `.ts` 文件(共 21 个):
✅ **主 src 下的文件**(7 个):
- `src/1.基础输出.ts`
- `src/2.一个带有记忆历史的可以反复对话的Agent.ts`
- `src/3.尝试使用system.ts`
- `src/4.使用Model Message的 system类型.ts`
- `src/5.封装call Model返回值为完全的响应文本.ts`
- `src/6.手动agent loop实现.ts`
>
> ive/` 下的历史归档文件**(5 个):
- `src/achive/1.基础输出.ts`
- `src/achive/2.一个带有记忆历史的可以反复对话的Agent.ts`
- `src/achive/3.尝试使用system.ts`
- `src/achive/4.使用Model Message的 system类型.ts`
- `src/achive/5.封装call Model返回值为完全的响应文本.ts`
✅ **其他模块化源码文件**(9 个):
- `src/budge/index.ts`
- `src/detect/helper.ts`
- `src/detect/index.ts`
- `src/detect/types.ts`
- `src/index.ts`
- `src/mock-model/index.ts`
- `src/retry/constants.ts`
- `src/retry/help.ts`
- `src/tools/get_weather.ts`
- `src/tools/tool-register.ts`
- `src/tools/utility-tools.ts`
(注:实际计数为 21 个,上述列表已全部列出)
如需进一步操作(例如查看某个文件内容、搜索某关键词、或批量重命名/整理),欢迎随时告诉我! 😊
【==================================结束Loop2==================================】
2230/15000
You:
3. grep:搜内容比找文件更重要
模型要改一个 名字
第一步不是读整全部目录的整个文件(可能读一个写了小说的文件夹,想全局改主角名字)
而是 grep 找到名字在哪里。
在文件系统中递归搜索匹配指定正则表达式的文本内容。
/**
* grep工具实现
* 在指定路径下递归搜索匹配正则表达式的文本行
* 返回格式:"相对路径:行号: 匹配内容"
*/
export const grepTool: ToolDefinition = {
// 工具唯一标识
name: 'grep',
// 工具描述(用于AI理解和用户提示)
description: '在文件中搜索匹配指定模式的内容。返回匹配的行号和内容',
// 参数定义(JSON Schema格式,用于参数校验和自动生成UI)
parameters: {
type: 'object',
properties: {
// 搜索模式(必填)
pattern: { type: 'string', description: '搜索模式(正则表达式)' },
// 搜索路径(可选,默认当前目录)
path: { type: 'string', description: '搜索路径(文件或目录),默认当前目录' },
},
required: ['pattern'],
additionalProperties: false, // 禁止传入未定义的参数
},
// 并发安全标记:多个请求可以同时执行此工具,不会互相干扰
isConcurrencySafe: true,
// 只读标记:此工具不会修改文件系统,可安全执行
isReadOnly: true,
// 最大返回字符数:防止返回过大结果导致内存问题
maxResultChars: 3000,
/**
* 工具执行入口
* @param args 工具参数
* @returns 匹配结果字符串
*/
execute: async ({ pattern, path = '.' }: { pattern: string; path?: string }) => {
// 将输入路径解析为绝对路径,确保后续操作一致性
const baseDir = resolve(path);
// 创建不区分大小写的正则表达式
// 注意:这里使用RegExp构造函数,用户输入的pattern会被当作正则表达式处理
const regex = new RegExp(pattern, 'i');
// 存储所有匹配结果
const matches: string[] = [];
// --------------------------
// 配置项:需要跳过的目录和文件
// --------------------------
/** 需要跳过的目录名称集合 */
const SKIP_DIRECTORIES = new Set(['node_modules', '.git', 'dist']);
/** 需要跳过的二进制文件扩展名集合 */
const BINARY_EXTENSIONS = new Set([
'.png', '.jpg', '.jpeg', '.gif', '.bmp', '.webp', // 图片
'.woff', '.woff2', '.ttf', '.eot', // 字体
'.ico', '.svg', // 图标
'.lock', // 锁文件(内容大且无搜索价值)
'.zip', '.rar', '.7z', '.tar', '.gz', // 压缩包
'.exe', '.dll', '.so', '.dylib' // 可执行文件
]);
// --------------------------
// 核心函数1:搜索单个文件
// --------------------------
/**
* 在单个文件中搜索匹配正则表达式的行
* @param filePath 文件的绝对路径
*/
function searchFile(filePath: string) {
// 提前终止:达到最大结果数时立即返回
if (matches.length >= 50) return;
// 获取文件扩展名
const ext = filePath.slice(filePath.lastIndexOf('.'));
// 跳过二进制文件
if (BINARY_EXTENSIONS.has(ext)) return;
// 读取文件内容(UTF-8编码)
// 注意:使用try-catch捕获读取错误(如权限不足、文件已删除等)
let content: string;
try {
content = readFileSync(filePath, 'utf-8');
} catch (error) {
// 静默跳过无法读取的文件,不中断整体搜索
return;
}
// 将文件内容按行分割
const lines = content.split('\n');
// 计算文件相对于搜索根目录的路径,输出更友好
const relativePath = relative(baseDir, filePath);
// 逐行检查匹配
for (let lineNumber = 0; lineNumber < lines.length; lineNumber++) {
if (regex.test(lines[lineNumber])) {
// 格式化结果:相对路径:行号(从1开始): 匹配内容(去除末尾空白)
matches.push(`${relativePath}:${lineNumber + 1}: ${lines[lineNumber].trimEnd()}`);
// 再次检查结果数,达到上限立即终止循环
if (matches.length >= 50) return;
}
}
}
// --------------------------
// 核心函数2:递归遍历目录
// --------------------------
/**
* 递归遍历目录,对每个文件调用searchFile
* @param dir 当前遍历的目录绝对路径
*/
function walkDirectory(dir: string) {
// 提前终止:达到最大结果数时立即返回
if (matches.length >= 50) return;
// 读取目录下的所有条目
let entries: string[];
try {
entries = readdirSync(dir);
} catch (error) {
// 静默跳过无法读取的目录
return;
}
// 遍历每个条目
for (const entryName of entries) {
// 跳过配置的排除目录
if (SKIP_DIRECTORIES.has(entryName)) continue;
// 拼接完整路径
const fullPath = join(dir, entryName);
try {
// 获取文件/目录状态
const stat = statSync(fullPath);
if (stat.isDirectory()) {
// 如果是目录,递归遍历
walkDirectory(fullPath);
} else {
// 如果是文件,搜索内容
searchFile(fullPath);
}
} catch (error) {
// 静默跳过无法获取状态的条目(如符号链接指向不存在的文件)
continue;
}
}
}
// --------------------------
// 主逻辑入口
// --------------------------
// 获取搜索路径的状态
const pathStat = statSync(baseDir);
if (pathStat.isFile()) {
// 如果是单个文件,直接搜索
searchFile(baseDir);
} else {
// 如果是目录,递归遍历
walkDirectory(baseDir);
}
// --------------------------
// 结果处理与返回
// --------------------------
if (matches.length === 0) {
// 无匹配结果
return `没有找到匹配 "${pattern}" 的内容`;
}
// 结果截断提示:当达到50条上限时显示
const truncationSuffix = matches.length >= 50
? '\n... (结果已截断,共 50+ 条匹配,请缩小搜索范围)'
: '';
// 将所有匹配结果用换行符连接后返回
return matches.join('\n') + truncationSuffix;
},
};
这个函数每次只处理50条匹配到的,超出的部分则返回告诉AI,结果是截断的,还没处理完的,这样LLM 下次还会在此执行这个tool 【这里注意一般都是搭配着编辑的工具去玩的,比如先查出来50个,编辑完了,下次再查,刚刚的50个已经编辑完了,自然下次grep就是后面的了】
1. 初始化
↓
清空结果数组 → 解析参数 → 标准化路径 → 编译正则 → 加载排除规则
2. 入口判断
↓
├─ 是单个文件 → 进入【搜索单个文件】
└─ 是目录 → 进入【递归遍历目录】
3. 递归遍历目录(walk函数)
↓
🔴 【检查1】够50条?→ 是:立刻终止所有遍历,跳转到【返回结果】
↓
读取目录条目 → 跳过排除目录
↓
├─ 子目录 → 递归回到【递归遍历目录】
└─ 文件 → 进入【搜索单个文件】
4. 搜索单个文件(searchFile函数)
↓
🔴 【检查2】够50条?→ 是:跳过该文件,返回上一级
↓
跳过二进制文件 → 读取文件内容
↓
逐行匹配正则
↓
匹配成功 → 存入结果数组
↓
🔴 【检查3】够50条?→ 是:立刻终止所有搜索,跳转到【返回结果】
5. 全部处理完成(未达到50条)
↓
跳转到【返回结果】
6. 返回结果(给Agent的明确信号)
↓
0条 → ✅ 全部搜完,无匹配
1-49条 → ✅ 全部搜完,这是所有结果
≥50条 → ⚠️ 已强行停止!还有更多未搜索,请再次调用
然后我准备了一篇文章
src/李白小说/c1/1.txt
我穿越到了唐朝,第一个想见的人就是李白。
我在长安的酒肆里四处打听李白的下落。
店小二说,李白刚刚还在这里喝酒。
我追出门去,远远看到了李白的背影。
李白穿着一身白衣,走在长安的街道上。
我快步上前,叫住了李白。
李白转过身,疑惑地看着我。
我告诉李白,我是他千年后的粉丝。
李白听了,哈哈大笑起来。
李白邀请我和他一起喝酒。
我们坐在酒肆里,听李白讲他的故事。
李白说,他年轻时曾游历过很多地方。
李白去过蜀地,见过那里的奇山异水。
李白去过江南,欣赏过那里的烟雨风光。
李白还去过塞外,感受过那里的大漠孤烟。
我问李白,他最喜欢哪里的风景。
李白说,他最喜欢的还是长安的月亮。
李白举起酒杯,对着月亮一饮而尽。
那一刻,我觉得李白就像月亮一样明亮。
我暗暗庆幸,能有机会见到李白。
查找所有李白出现的位置
─░▒▓ ~/agent-sdy on main !1691 ?46 ▓▒░······························································░▒▓ INT ✘ took 1m 2s at 03:57:29 PM ▓▒░
╰─ npm run start
> agent-sdy@1.0.0 start
> tsx src/index.ts
You: '/Users/cunwangbro/agent-sdy/src/李白小说'查看李白出现的地方
【==================================开始Loop_1_==================================】
图书馆有1个人
正在调用工具grep call_ff2ba85b11ff4863a7b42d
【==================================看来还需要多一轮,来处理本轮"grep"的调用结果==================================】
[并发] grep 获取共享锁
图书馆有0个人
【==================================调用工具结果c1/1.txt:1: 我穿越到了唐朝,第一个想见的人就是李白。
c1/1.txt:2: 我在长安的酒肆里四处打听李白的下落。
c1/1.txt:3: 店小二说,李白刚刚还在这里喝酒。
c1/1.txt:4: 我追出门去,远远看到了李白的背影。
c1/1.txt:5: 李白穿着一身白衣,走在长安的街道上。
c1/1.txt:6: 我快步上前,叫住了李白。
c1/1.txt:7: 李白转过身,疑惑地看着我。
c1/1.txt:8: 我告诉李白,我是他千年后的粉丝。
c1/1.txt:9: 李白听了,哈哈大笑起来。
c1/1.txt:10: 李白邀请我和他一起喝酒。
c1/1.txt:11: 我们坐在酒肆里,听李白讲他的故事。
c1/1.txt:12: 李白说,他年轻时曾游历过很多地方。
c1/1.txt:13: 李白去过蜀地,见过那里的奇山异水。
c1/1.txt:14: 李白去过江南,欣赏过那里的烟雨风光。
c1/1.txt:15: 李白还去过塞外,感受过那里的大漠孤烟。
c1/1.txt:16: 我问李白,他最喜欢哪里的风景。
c1/1.txt:17: 李白说,他最喜欢的还是长安的月亮。
c1/1.txt:18: 李白举起酒杯,对着月亮一饮而尽。
c1/1.txt:19: 那一刻,我觉得李白就像月亮一样明亮。
c1/1.txt:20: 我暗暗庆幸,能有机会见到李白。==================================】
【==================================结束Loop1==================================】
946/15000
【==================================开始Loop_2_==================================】
在文件 `c1/1.txt` 中,"李白" 出现在第 1 行到第 20 行,共 **20 处**。内容涵盖你穿越唐朝与李白相遇、交谈、听他讲述游历故事等情节。
如需进一步分析(例如统计出现频次、提取上下文、修改某处“李白”为其他称呼等),请告诉我!
【==================================结束Loop2==================================】
2414/15000
You:
4. Bash 工具
bash 是万能工具——能跑测试、能装依赖、能查环境、能做任何 shell 能做的事。但也正因为如此,它是最危险的。一个 rm -rf / 就能把系统搞挂。
export const bashTool: ToolDefinition = {
name: 'bash',
description: '执行 shell 命令并返回输出。适合运行脚本、检查环境、执行构建等操作',
parameters: {
type: 'object',
properties: {
command: { type: 'string', description: '要执行的 shell 命令' },
},
required: ['command'],
additionalProperties: false,
},
isConcurrencySafe: false,
isReadOnly: false,
maxResultChars: 3000,
execute: async ({ command }) => {
// 先检测环境是否支持 child_process
try {
execSync('echo test', { stdio: 'ignore' });
} catch {
return `[bash 不可用] 当前环境不支持 shell 命令。本地终端运行可使用。`;
}
try {
const output = execSync(command, {
encoding: 'utf-8',
timeout: 10000, // 10 秒超时
maxBuffer: 1024 * 1024,
});
return output || '(命令执行成功,无输出)';
} catch (err: any) {
return `命令执行失败 (exit ${err.status || 1}):\n${err.stderr || err.message}`;
}
},
};
超时 10 秒:防止模型跑一个 while true 卡死整个进程。生产环境通常更长(30-60 秒),但演示用 10 秒够了,你可以自行调整。
环境检测:WebContainer(浏览器沙箱)里 child_process 不可用,所以 execute 一开始先检测环境。不可用就直接返回提示信息,不 crash。
isConcurrencySafe: false:bash 命令可能有副作用(创建文件、修改环境变量),所以默认串行。生产级 Agent 会更精细——分析命令内容判断是否只读(ls、cat 可以并发,rm、mv 必须串行),但那个逻辑比较复杂,后面权限系统那篇再加。
╭─░▒▓ ~/agent-sdy on main !1691 ?46 ▓▒░···········································································░▒▓ INT ✘ at 04:10:20 PM ▓▒░
╰─ npm run start
> agent-sdy@1.0.0 start
> tsx src/index.ts
You: '/Users/cunwangbro/agent-sdy/src/李白小说' 重复内容的文件删掉,保留一个即可
【==================================开始Loop_1_==================================】
要删除重复内容的文件并只保留一个,我们需要:
1. **找出目录中所有文件**(可能包括子目录);
2. **计算每个文件的内容哈希值(如 SHA-256)**,以判断内容是否完全相同;
3. **识别重复哈希值的文件组**;
4. **对每组重复文件,保留一个(如字典序最小路径),其余删除**。
但当前工具集**不直接支持计算文件哈希**,也没有 `find_duplicates_by_content` 工具。不过我们可以组合使用以下工具达成目标:
✅ 可行策略(基于现有工具):
- 用 `glob` 列出所有文件(如 `**/*`,排除目录);
- 用 `read_file` 逐个读取文件内容(需注意大文件可能超限,但假设小说文本文件不大);
- 在推理层对内容做哈希或直接字符串比较(模型可处理小到中等文件);
- 然后调用 `bash` 执行 `rm` 删除冗余文件。
⚠️ 风险提示:
- 直接 `rm` 有破坏性,需谨慎;应先**预览哪些文件将被删除**;
- `/Users/cunwangbro/agent-sdy/src/李白小说` 路径含中文和空格,shell 命令需正确转义。
我们分步进行:
### 步骤 1:列出该目录下所有文件(非目录)
先确认路径是否存在、有哪些文件:
图书馆有1个人
正在调用工具list_directory call_bebdd99c25944ca48dc5eb
【==================================看来还需要多一轮,来处理本轮"list_directory"的调用结果==================================】
[并发] list_directory 获取共享锁
图书馆有0个人
【==================================调用工具结果[FILE] .DS_Store
[DIR] c1
[DIR] c1 copy==================================】
【==================================结束Loop1==================================】
1374/1500000
【==================================开始Loop_2_==================================】
目录结构如下:
- `.DS_Store`(macOS 元数据,可忽略或稍后删)
- `c1`(目录)
- `c1 copy`(目录)
你提到“重复内容的文件”,而目前看到的是两个**同名但带 `copy` 的目录**:`c1` 和 `c1 copy`。很可能这两个目录内容完全相同(或高度相似),需确认并去重。
我们继续:
### 步骤 2:检查 `c1` 和 `c1 copy` 是否内容一致
→ 使用 `glob` 分别列出两目录下所有文件路径(扁平化),再用 `read_file` 抽样比对(如各取前几文件);或更高效地:用 `bash` 执行 `diff -r`(递归比较目录)——这是最可靠方式。
让我们运行 `diff -r` 比较两个目录:
需要独占锁的write_file 尝试执行
需要独占锁的write_file 可以执行了
正在调用工具bash call_4bb30f156d034a8f8ed4b6
【==================================看来还需要多一轮,来处理本轮"bash"的调用结果==================================】
[串行] bash 获取独占锁,等待其他工具完成
【==================================调用工具结果Only in /Users/cunwangbro/agent-sdy/src/李白小说/c1 copy: c1
==================================】
【==================================结束Loop2==================================】
3044/1500000
【==================================开始Loop_3_==================================】
`diff -r` 输出显示:
```
Only in /Users/cunwangbro/agent-sdy/src/李白小说/c1 copy: c1
```
说明 `c1 copy` 目录里**多了一个名为 `c1` 的子目录**(即嵌套了 `c1/c1/...`),而 `c1` 目录本身没有该子目录。这**不是内容完全重复**,而是结构不同 —— `c1 copy` 可能是误复制导致的嵌套。
但你的原始需求是:“重复内容的文件删掉,保留一个即可”。所以我们应聚焦于**真正内容重复的文件**(而非目录名相似)。
为严谨起见,我们:
✅ 步骤 3:递归收集所有**文件路径**(排除目录),再按内容分组
→ 使用 `find` + `sha256sum`(需 `bash`),这是标准做法:
需要独占锁的write_file 尝试执行
需要独占锁的write_file 可以执行了
正在调用工具bash call_8343cbf680984bef95f492
【==================================看来还需要多一轮,来处理本轮"bash"的调用结果==================================】
[串行] bash 获取独占锁,等待其他工具完成
【==================================调用工具结果0c0635b6bca1c843ded6bd10a27ee0110ac49e8370e5382122e9b9cb578950a6 /Users/cunwangbro/agent-sdy/src/李白小说/c1 copy/1.txt
0c0635b6bca1c843ded6bd10a27ee0110ac49e8370e5382122e9b9cb578950a6 /Users/cunwangbro/agent-sdy/src/李白小说/c1 copy/c1/1.txt
0c0635b6bca1c843ded6bd10a27ee0110ac49e8370e5382122e9b9cb578950a6 /Users/cunwangbro/agent-sdy/src/李白小说/c1/1.txt
c6e53225f8313b76c66115e08ac522c239edd848c8c12f34748ed8ecf1a40249 /Users/cunwangbro/agent-sdy/src/李白小说/.DS_Store
==================================】
【==================================结束Loop3==================================】
5017/1500000
【==================================开始Loop_4_==================================】
✅ 成功识别重复内容文件!
哈希 `0c0635b6...` 对应 **3 个文件**,内容完全相同:
- `/Users/cunwangbro/agent-sdy/src/李白小说/c1 copy/1.txt`
- `/Users/cunwangbro/agent-sdy/src/李白小说/c1 copy/c1/1.txt`
- `/Users/cunwangbro/agent-sdy/src/李白小说/c1/1.txt`
而 `.DS_Store` 是唯一哈希,无需处理。
### ✅ 决策(保留一个,删两个):
按路径字典序最小者保留 →
`/Users/cunwangbro/agent-sdy/src/李白小说/c1/1.txt` 是三者中**路径最短、最规范**的,应保留。
删除其余两个:
- `/Users/cunwangbro/agent-sdy/src/李白小说/c1 copy/1.txt`
- `/Users/cunwangbro/agent-sdy/src/李白小说/c1 copy/c1/1.txt`
⚠️ 注意:`c1 copy/c1/1.txt` 路径含空格和中文,需用单引号包裹。
执行删除:
需要独占锁的write_file 尝试执行
需要独占锁的write_file 可以执行了
正在调用工具bash call_863bc4adfa9d412e8a0547
【==================================看来还需要多一轮,来处理本轮"bash"的调用结果==================================】
[串行] bash 获取独占锁,等待其他工具完成
【==================================调用工具结果(命令执行成功,无输出)==================================】
【==================================结束Loop4==================================】
7644/1500000
【==================================开始Loop_5_==================================】
✅ 已成功删除重复内容的两个文件:
- `/Users/cunwangbro/agent-sdy/src/李白小说/c1 copy/1.txt`
- `/Users/cunwangbro/agent-sdy/src/李白小说/c1 copy/c1/1.txt`
仅保留唯一源文件:
📁 `/Users/cunwangbro/agent-sdy/src/李白小说/c1/1.txt`
如需进一步检查是否还有其他重复文件(例如 `2.txt`, `3.txt` 等),可运行完整去重脚本,或告知我继续扫描。
是否需要我:
- ✅ 列出当前目录下所有剩余文件?
- ✅ 检查 `c1 copy/` 目录是否还有其他冗余内容(如空子目录)?
- ✅ 清理 `.DS_Store` 文件?
请告诉我 👇
【==================================结束Loop5==================================】
10479/1500000
You:
可以看到这个大模型还是很聪明的,我的目标是删除重复内容的文件
他并没有用read file 而是全都把文件内容通过bash命令hash SHA-256 哈希值来判断重复的
在 Loop 3 中,通过bash工具运行了这条命令:
find "/Users/cunwangbro/agent-sdy/src/李白小说" -type f -exec sha256sum {} \;
这条命令的作用:
find ... -type f:递归遍历指定目录下的所有文件(排除目录)-exec sha256sum {} \;:对每个找到的文件,计算其SHA-256 哈希值
哈希判断重复的原理
SHA-256 是一种密码学哈希函数,它有两个关键特性:
- 相同内容 → 相同哈希:无论文件名、路径、修改时间如何,只要文件内容完全一致,计算出的哈希值就会完全相同
- 不同内容 → 不同哈希:哪怕文件内容只有一个字节的差异,哈希值也会完全不同(碰撞概率几乎为零)
0c0635b6bca1c843ded6bd10a27ee0110ac49e8370e5382122e9b9cb578950a6 /Users/cunwangbro/agent-sdy/src/李白小说/c1 copy/1.txt
0c0635b6bca1c843ded6bd10a27ee0110ac49e8370e5382122e9b9cb578950a6 /Users/cunwangbro/agent-sdy/src/李白小说/c1 copy/c1/1.txt
0c0635b6bca1c843ded6bd10a27ee0110ac49e8370e5382122e9b9cb578950a6 /Users/cunwangbro/agent-sdy/src/李白小说/c1/1.txt
这三个文件拥有完全相同的 SHA-256 哈希值,证明它们的内容是100% 完全相同的,没有任何差异。
到这里,Agent 的工具箱从 5 个扩充到了 9 个。来看看完整阵容:
| 工具 | 用途 | 并发 | 只读 |
|---|---|---|---|
| get_weather | 查天气(演示用) | 可并发 | 只读 |
| calculator | 数学计算 | 可并发 | 只读 |
| read_file | 读文件 | 可并发 | 只读 |
| write_file | 写文件 | 串行 | 读写 |
| list_directory | 列目录 | 可并发 | 只读 |
| edit_file | 精确编辑 | 串行 | 读写 |
| glob | 文件搜索 | 可并发 | 只读 |
| grep | 内容搜索 | 可并发 | 只读 |
| bash | 命令执行 | 串行 | 读写 |